多 Agent 框架¶
⚠️ 时效性说明:本章涉及前沿模型/价格/榜单等信息,可能随版本快速变化;请以论文原文、官方发布页和 API 文档为准。 ✅ 2026-03-27 复核说明:本章已按 LangGraph、Agno、CrewAI、AutoGen 与 Microsoft Agent Framework 官方材料核对。教学示例默认使用
gpt-5-mini作为子 Agent / 执行角色模型,关键规划或管理角色可升级为gpt-5.4。AutoGen 官方 stable 文档仍在维护,但 Microsoft 当前统一新路线已转向 Microsoft Agent Framework。
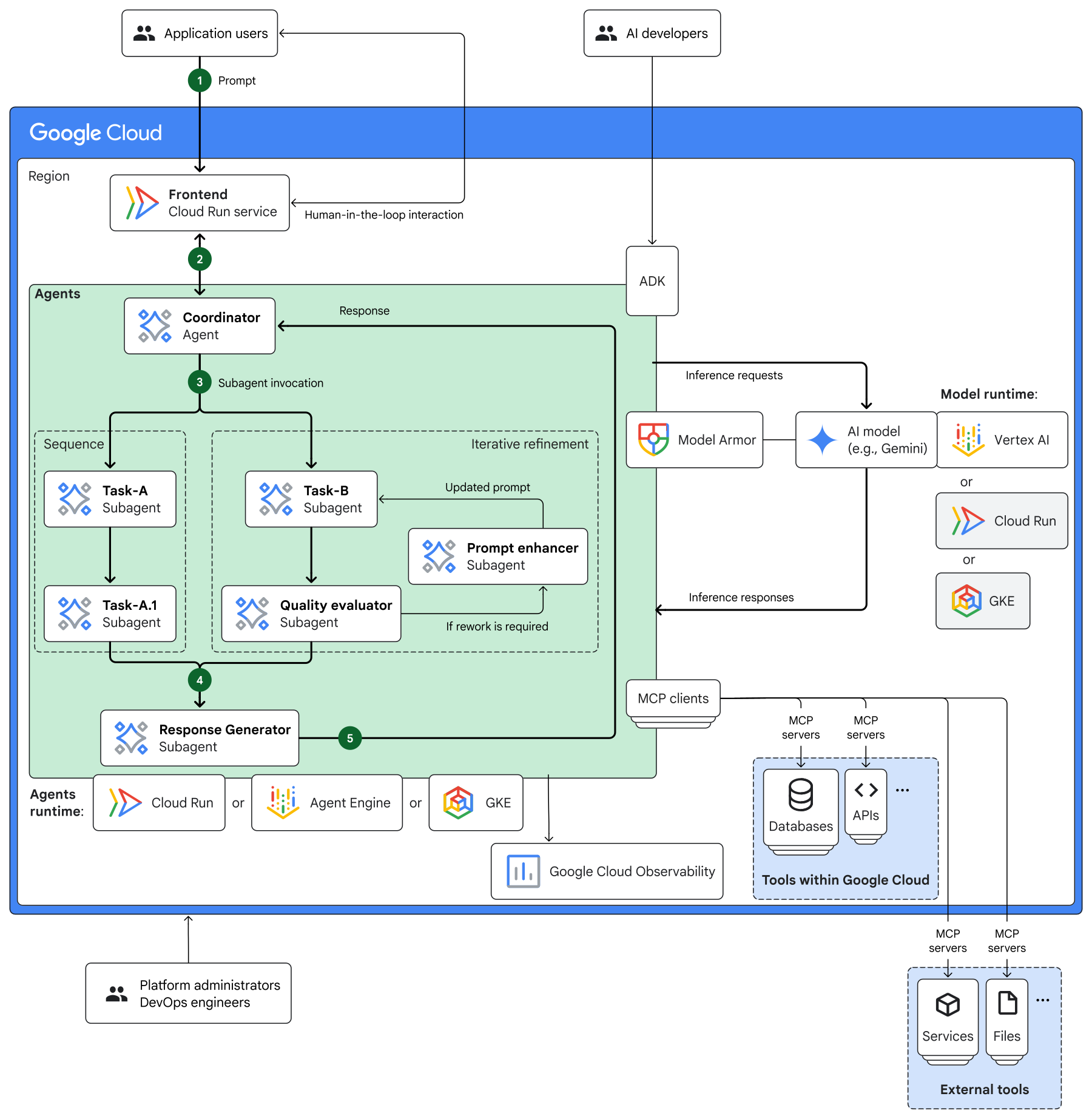
图源:Google Cloud Architecture Center - Multi-agent AI system in Google Cloud,许可:CC BY 4.0。这里用真实生产架构替换原占位导图,帮助理解协调者、子 Agent、工具接入与可观测性闭环。
📌 当单个 Agent 无法胜任复杂任务时,多 Agent 系统通过角色分工、协作对话、工作流编排实现"1+1>2"的效果。 LangGraph 、 Agno 、 CrewAI 、 AutoGen 是当前最常见的代表性多 Agent 框架,本章也补充 Microsoft Agent Framework 的当前状态。
📌 定位说明:本章侧重多 Agent框架对比与使用( LangGraph/Agno/CrewAI/AutoGen )。 - 多 Agent 系统编码实战(架构实现、 A2A 通信、项目开发)→ AI Agent 开发实战/04-多 Agent 系统与实战 - 新一代 Agent 前沿研究( Manus/Claude Code 等)→ LLM 学习/04-前沿探索/15-新一代 AI Agent
🎯 学习目标¶
- 理解多 Agent 系统的核心动机与设计原则
- 掌握 ReAct 、 Plan-and-Execute 、 Reflection 等 Agent 设计模式
- 深入掌握 LangGraph 的 StateGraph 编程模型与工作流编排
- 理解 Agno 的 Team / Workflow / AgentOS 抽象与使用方式
- 熟练使用 CrewAI 的 Agent/Task/Crew 三层抽象
- 了解 AutoGen 的多 Agent 对话模式,以及它与 Microsoft Agent Framework、AG2 的关系
- 能够根据场景选择合适的框架
- 掌握多 Agent 系统面试高频考点
17.1 多 Agent 系统概述¶
17.1.1 为什么需要多 Agent¶
单个 Agent 在面对复杂任务时存在明显局限:
| 局限性 | 描述 | 多 Agent 解决方案 |
|---|---|---|
| 上下文窗口受限 | 单次对话难以容纳所有信息 | 不同 Agent 处理不同子任务 |
| 角色混乱 | 同时扮演多角色时质量下降 | 每个 Agent 专注单一角色 |
| 工具调用复杂 | 工具过多导致选择困难 | Agent 各自持有相关工具 |
| 推理链过长 | 多步推理容易出错 | 分解为短推理链协作执行 |
| 缺乏自我纠错 | 无法有效反思输出质量 | 专门的 Critic Agent 审查 |
多 Agent 系统的核心思想:将复杂任务分解为子任务,由专门化的 Agent 分工协作完成。
┌──────────────────────────────────────────────┐
│ Orchestrator / Router │
│ (编排器:分配任务、协调结果) │
└─────┬──────────┬──────────┬─────────────┬────┘
│ │ │ │
┌───▼───┐ ┌──▼───┐ ┌──▼────┐ ┌────▼───┐
│Planner│ │Coder │ │Critic │ │Reporter│
│(规划) │ │(编码) │ │(审查) │ │(汇报) │
└───────┘ └──────┘ └───────┘ └────────┘
17.1.2 多 Agent 架构模式¶
1. 顺序流水线( Sequential Pipeline )
Agent 按固定顺序执行,前一个的输出是后一个的输入:
2. 层级委派( Hierarchical )
Supervisor Agent 分配任务, Worker Agent 执行:
3. 协作对话( Collaborative Chat )
多个 Agent 在共享对话中轮流发言、协商:
4. 竞争投票( Competitive/Voting )
多个 Agent 独立完成同一任务,取最优或投票:
17.2 Agent 设计模式¶
17.2.1 ReAct ( Reasoning + Acting )¶
ReAct 模式让 Agent 交替进行推理( Thought )和行动( Action ),是最基础的 Agent 模式。
"""ReAct模式核心实现 - 使用 LangGraph 现代API"""
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import create_react_agent
from langchain_core.tools import tool
@tool
def search_web(query: str) -> str:
"""搜索互联网获取最新信息"""
# 实际项目中接入搜索API
return f"搜索 '{query}' 的结果:相关信息..."
@tool
def calculator(expression: str) -> str:
"""计算数学表达式(使用AST安全解析)"""
import ast
try:
tree = ast.parse(expression, mode='eval')
for node in ast.walk(tree):
if not isinstance(node, (ast.Expression, ast.BinOp, ast.UnaryOp,
ast.Constant, ast.Add, ast.Sub, ast.Mult,
ast.Div, ast.Mod, ast.Pow, ast.USub)):
return f"计算错误: 不允许的表达式"
return str(eval(compile(tree, '<expr>', 'eval'), {"__builtins__": {}}, {}))
except Exception as e:
return f"计算错误: {e}"
# 使用 LangGraph 创建 ReAct Agent
llm = ChatOpenAI(model="gpt-5-mini", temperature=0)
agent = create_react_agent(
model=llm,
tools=[search_web, calculator]
)
# 调用 Agent(使用 messages 格式)
result = agent.invoke({
"messages": [{"role": "user", "content": "2024年中国GDP总量是多少万亿人民币?折合多少万亿美元?"}]
})
print(result["messages"][-1].content)
API 迁移说明
langchain.agents.AgentExecutor 和 langchain.agents.create_react_agent 已弃用。 请使用 LangGraph 的 langgraph.prebuilt.create_react_agent。
17.2.2 Plan-and-Execute¶
先制定完整计划,再逐步执行,适合多步骤复杂任务:
"""Plan-and-Execute模式"""
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from pydantic import BaseModel, Field
class Plan(BaseModel): # Pydantic BaseModel:自动数据验证和序列化
"""任务规划"""
steps: list[str] = Field(description="执行步骤列表")
class StepResult(BaseModel):
"""步骤执行结果"""
step: str
result: str
success: bool
llm = ChatOpenAI(model="gpt-5.4", temperature=0)
# Planner:生成计划
planner_prompt = ChatPromptTemplate.from_messages([
("system", "你是一个任务规划专家。将复杂任务分解为可执行的步骤列表。"),
("human", "请为以下任务制定执行计划:\n{task}")
])
planner_chain = planner_prompt | llm.with_structured_output(Plan)
# Executor:执行单个步骤
executor_prompt = ChatPromptTemplate.from_messages([
("system", "你是一个任务执行专家。根据计划执行当前步骤。\n已完成步骤的结果:{previous_results}"),
("human", "当前步骤:{current_step}")
])
executor_chain = executor_prompt | llm
# Re-Planner:根据执行结果调整计划
def plan_and_execute(task: str) -> str:
# Step 1: 生成计划
plan = planner_chain.invoke({"task": task})
print(f"📋 计划步骤: {plan.steps}")
results = []
for i, step in enumerate(plan.steps): # enumerate同时获取索引和元素
print(f"\n🔄 执行步骤 {i+1}: {step}")
result = executor_chain.invoke({
"current_step": step,
"previous_results": "\n".join([f"- {r}" for r in results]) or "无"
})
results.append(f"步骤{i+1}({step}): {result.content}")
print(f"✅ 结果: {result.content[:100]}...")
return results[-1] if results else "无结果" # [-1]负索引取最后一个元素
# 使用
final = plan_and_execute("分析某电商平台的用户评论数据,生成产品改进建议报告")
17.2.3 Reflection / Reflexion¶
Agent 执行后进行自我反思,利用反馈改进输出:
"""Reflection模式:生成-反思-改进循环"""
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, AIMessage
llm = ChatOpenAI(model="gpt-5-mini", temperature=0.7)
def reflection_loop(task: str, max_iterations: int = 3) -> str:
"""反思循环:生成 → 反思 → 改进"""
# 初始生成
generator_messages = [
{"role": "system", "content": "你是一个专业写作助手,生成高质量内容。"},
{"role": "user", "content": task}
]
draft = llm.invoke(generator_messages).content
print(f"📝 初始草稿:\n{draft[:200]}...\n")
for i in range(max_iterations):
# 反思:评估当前输出
critic_messages = [
{"role": "system", "content": """你是一个严格的内容审查专家。
请从以下维度评分(1-10)并给出具体改进建议:
1. 准确性 2. 完整性 3. 清晰度 4. 结构性
如果所有维度均≥8分,回复"APPROVED"。"""},
{"role": "user", "content": f"请审查以下内容:\n\n{draft}"}
]
critique = llm.invoke(critic_messages).content
print(f"🔍 第{i+1}轮反思:\n{critique[:200]}...\n")
if "APPROVED" in critique:
print(f"✅ 第{i+1}轮通过审查")
break
# 改进:根据反思结果修改
improve_messages = [
{"role": "system", "content": "根据审查意见改进内容,保持原有优点,修正不足。"},
{"role": "user", "content": f"原始内容:\n{draft}\n\n审查意见:\n{critique}\n\n请生成改进版本:"}
]
draft = llm.invoke(improve_messages).content
print(f"📝 改进版本 {i+1}:\n{draft[:200]}...\n")
return draft
result = reflection_loop("写一篇关于Transformer架构的技术博客摘要(300字)")
17.2.4 Multi-Agent Collaboration¶
多 Agent 协作处理复杂任务,每个 Agent 有明确分工:
17.3 LangGraph 深入教程¶
17.3.1 StateGraph 核心概念¶
LangGraph 是 LangChain 团队开发的 Agent 编排框架,基于有向图实现复杂工作流。
四大核心概念:
| 概念 | 说明 | 类比 |
|---|---|---|
| State | 图的全局状态,在节点间流转 | 流水线上的"产品" |
| Node | 执行具体逻辑的函数 | 流水线上的"工位" |
| Edge | 节点间的连接关系 | 流水线上的"传送带" |
| Conditional Edge | 根据状态决定下一步走向 | 流水线上的"分拣机" |
"""LangGraph核心概念演示"""
# pip install langgraph langchain-openai
from typing import Annotated, TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain_openai import ChatOpenAI
# 1. 定义State:使用TypedDict声明状态字段
class AgentState(TypedDict): # TypedDict定义类型化字典
messages: Annotated[list, add_messages] # 消息列表(自动追加)
current_step: str # 当前步骤
iteration_count: int # 迭代计数
# 2. 定义Node:普通Python函数,接收state返回更新
def researcher(state: AgentState) -> dict:
"""研究员节点"""
llm = ChatOpenAI(model="gpt-5-mini")
messages = state["messages"]
response = llm.invoke(messages)
return {
"messages": [response],
"current_step": "research_done"
}
def writer(state: AgentState) -> dict:
"""写作节点"""
llm = ChatOpenAI(model="gpt-5-mini")
messages = state["messages"] + [
{"role": "system", "content": "根据研究结果撰写报告"}
]
response = llm.invoke(messages)
return {
"messages": [response],
"current_step": "writing_done"
}
def reviewer(state: AgentState) -> dict:
"""审核节点"""
llm = ChatOpenAI(model="gpt-5.4")
messages = state["messages"] + [
{"role": "system", "content": "审核报告质量,回复PASS或REVISE并说明原因"}
]
response = llm.invoke(messages)
return {
"messages": [response],
"current_step": "review_done",
"iteration_count": state.get("iteration_count", 0) + 1
}
# 3. 定义Conditional Edge:根据状态决定路由
def should_revise(state: AgentState) -> str:
"""条件边:决定是否需要修改"""
last_message = state["messages"][-1].content
if "PASS" in last_message or state.get("iteration_count", 0) >= 3:
return "end"
return "revise"
# 4. 构建Graph
workflow = StateGraph(AgentState)
# 添加节点
workflow.add_node("researcher", researcher)
workflow.add_node("writer", writer)
workflow.add_node("reviewer", reviewer)
# 添加边
workflow.add_edge(START, "researcher") # 入口 → 研究
workflow.add_edge("researcher", "writer") # 研究 → 写作
workflow.add_edge("writer", "reviewer") # 写作 → 审核
# 添加条件边
workflow.add_conditional_edges(
"reviewer", # 从审核节点出发
should_revise, # 条件函数
{
"revise": "writer", # 需要修改 → 回到写作
"end": END # 通过 → 结束
}
)
# 编译
graph = workflow.compile()
# 执行
result = graph.invoke({
"messages": [{"role": "user", "content": "写一份关于AI Agent技术趋势的分析报告"}],
"current_step": "start",
"iteration_count": 0
})
17.3.2 工作流编排模式¶
顺序执行¶
workflow.add_edge(START, "step1")
workflow.add_edge("step1", "step2")
workflow.add_edge("step2", "step3")
workflow.add_edge("step3", END)
并行执行( Fan-out / Fan-in )¶
"""LangGraph并行执行模式"""
import operator
from typing import Annotated, TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.constants import Send
class ParallelState(TypedDict):
topic: str
research_results: Annotated[list[str], operator.add] # 并行结果合并
final_report: str
def create_research_tasks(state: ParallelState) -> list[Send]:
"""Fan-out: 创建并行研究任务"""
subtopics = ["技术分析", "市场分析", "竞品分析"]
return [Send("research_worker", {"topic": state["topic"], "subtopic": s}) for s in subtopics]
def research_worker(state: dict) -> dict:
"""并行研究worker"""
# 每个worker独立执行
result = f"[{state['subtopic']}] 关于{state['topic']}的研究结果..."
return {"research_results": [result]}
def synthesize(state: ParallelState) -> dict:
"""Fan-in: 合并并行结果生成最终报告"""
all_results = "\n".join(state["research_results"])
return {"final_report": f"综合报告:\n{all_results}"}
graph = StateGraph(ParallelState)
graph.add_node("research_worker", research_worker)
graph.add_node("synthesize", synthesize)
graph.add_conditional_edges(START, create_research_tasks, ["research_worker"])
graph.add_edge("research_worker", "synthesize")
graph.add_edge("synthesize", END)
app = graph.compile()
Human-in-the-Loop (人机协作)¶
"""LangGraph人机协作模式"""
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.memory import MemorySaver
from langchain_core.messages import HumanMessage
from typing import Annotated, TypedDict
from langgraph.graph.message import add_messages
class HumanLoopState(TypedDict):
messages: Annotated[list, add_messages] # Annotated附加元数据注解
needs_approval: bool
def generate_plan(state: HumanLoopState) -> dict:
"""生成执行计划,等待人类审批"""
plan = "计划:1. 收集数据 2. 分析趋势 3. 生成报告"
return {
"messages": [{"role": "assistant", "content": f"📋 {plan}"}],
"needs_approval": True
}
def execute_plan(state: HumanLoopState) -> dict:
"""执行经过人类审批的计划"""
return {"messages": [{"role": "assistant", "content": "✅ 计划已执行完成"}]}
def check_approval(state: HumanLoopState) -> str:
"""检查人类是否批准"""
last_msg = state["messages"][-1]
if hasattr(last_msg, 'content') and "同意" in last_msg.content: # hasattr检查对象是否有某属性
return "approved"
return "rejected"
workflow = StateGraph(HumanLoopState)
workflow.add_node("generate_plan", generate_plan)
workflow.add_node("execute_plan", execute_plan)
workflow.add_edge(START, "generate_plan")
# interrupt_before: 执行前暂停,等待人类输入
workflow.add_conditional_edges("generate_plan", check_approval, {
"approved": "execute_plan",
"rejected": END
})
workflow.add_edge("execute_plan", END)
# 使用Checkpointer支持中断与恢复
memory = MemorySaver()
app = workflow.compile(checkpointer=memory, interrupt_before=["execute_plan"])
# 第一次运行:生成计划后暂停
config = {"configurable": {"thread_id": "approval-1"}}
result = app.invoke(
{"messages": [HumanMessage(content="帮我分析今年的AI市场趋势")]},
config=config
)
print("当前状态:", result)
# 人类审批后恢复执行
app.invoke(
{"messages": [HumanMessage(content="同意执行")]},
config=config
)
17.3.3 Checkpointing 与状态持久化¶
"""LangGraph Checkpointing"""
from langgraph.checkpoint.memory import MemorySaver # 内存存储
from langgraph.checkpoint.sqlite import SqliteSaver # SQLite持久化
# from langgraph.checkpoint.postgres import PostgresSaver # 生产级PostgreSQL
# 内存Checkpoint(开发/测试用)
memory_saver = MemorySaver()
# SQLite Checkpoint(单机持久化)
import sqlite3
conn = sqlite3.connect("checkpoints.db", check_same_thread=False)
sqlite_saver = SqliteSaver(conn)
# 编译时指定checkpointer
app = workflow.compile(checkpointer=sqlite_saver)
# 执行时必须指定thread_id
config = {"configurable": {"thread_id": "session-001"}}
# 支持时间旅行:回溯到任意checkpoint
# state_history = list(app.get_state_history(config))
# app.update_state(config, values={"messages": [...]})
17.3.4 子图( SubGraph )与模块化¶
"""LangGraph SubGraph模块化设计"""
from typing import TypedDict, Annotated
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
# 子图State
class ResearchState(TypedDict):
messages: Annotated[list, add_messages]
sources: list[str]
# 构建子图
def build_research_subgraph() -> StateGraph:
"""构建研究子图"""
def search(state: ResearchState) -> dict:
return {"sources": ["论文A", "论文B"]}
def summarize(state: ResearchState) -> dict:
sources = state.get("sources", [])
return {"messages": [{"role": "assistant", "content": f"研究摘要(基于{len(sources)}篇来源)"}]}
subgraph = StateGraph(ResearchState)
subgraph.add_node("search", search)
subgraph.add_node("summarize", summarize)
subgraph.add_edge(START, "search")
subgraph.add_edge("search", "summarize")
subgraph.add_edge("summarize", END)
return subgraph.compile()
# 主图中使用子图作为节点
class MainState(TypedDict):
messages: Annotated[list, add_messages]
sources: list[str]
main = StateGraph(MainState)
main.add_node("research", build_research_subgraph()) # 子图作为节点
main.add_node("report", lambda s: {"messages": [{"role": "assistant", "content": "最终报告"}]}) # lambda匿名函数
main.add_edge(START, "research")
main.add_edge("research", "report")
main.add_edge("report", END)
app = main.compile()
17.3.5 Streaming 流式输出¶
"""LangGraph流式输出"""
from langgraph.graph import StateGraph, START, END
from typing import TypedDict, Annotated
from langgraph.graph.message import add_messages
class StreamState(TypedDict):
messages: Annotated[list, add_messages]
# 方式1: stream events(推荐)
async def stream_example(): # async def定义协程函数
app = workflow.compile()
async for event in app.astream_events(
{"messages": [{"role": "user", "content": "你好"}]},
version="v2"
):
kind = event["event"]
if kind == "on_chat_model_stream":
# 实时输出LLM token
content = event["data"]["chunk"].content
if content:
print(content, end="", flush=True)
elif kind == "on_chain_end":
print(f"\n[节点完成]: {event['name']}")
# 方式2: stream模式
# async for chunk in app.astream(inputs, stream_mode="values"):
# print(chunk["messages"][-1].content)
17.3.6 完整示例:多步研究 Agent¶
"""完整示例:基于LangGraph的多步研究Agent"""
from typing import TypedDict, Annotated, Literal
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langgraph.checkpoint.memory import MemorySaver
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
from langchain_core.tools import tool
from langgraph.prebuilt import ToolNode
import json
# --- 工具定义 ---
@tool
def web_search(query: str) -> str:
"""搜索互联网获取最新信息"""
return f"搜索结果:关于'{query}'的最新信息..."
@tool
def arxiv_search(query: str) -> str:
"""搜索arXiv学术论文"""
return f"arXiv结果:找到关于'{query}'的相关论文3篇..."
@tool
def write_report(title: str, content: str) -> str:
"""撰写研究报告"""
return f"📄 报告《{title}》已生成,共{len(content)}字"
tools = [web_search, arxiv_search, write_report]
tool_node = ToolNode(tools)
# --- State定义 ---
class ResearchAgentState(TypedDict):
messages: Annotated[list, add_messages]
research_topic: str
iteration: int
# --- 节点定义 ---
llm = ChatOpenAI(model="gpt-5-mini", temperature=0).bind_tools(tools)
def planner(state: ResearchAgentState) -> dict:
"""规划研究步骤"""
system = SystemMessage(content="""你是一个研究规划专家。
根据用户的研究主题,制定搜索计划。
使用web_search搜索最新资讯,arxiv_search搜索学术论文。
收集足够信息后使用write_report生成报告。""")
messages = [system] + state["messages"]
response = llm.invoke(messages)
return {"messages": [response]}
def should_continue(state: ResearchAgentState) -> Literal["tools", "end"]:
"""判断是否需要继续调用工具"""
last_message = state["messages"][-1]
if hasattr(last_message, "tool_calls") and last_message.tool_calls: # hasattr先检查属性是否存在,and短路求值再判断是否非空
return "tools"
return "end"
# --- 构建图 ---
workflow = StateGraph(ResearchAgentState)
workflow.add_node("planner", planner)
workflow.add_node("tools", tool_node)
workflow.add_edge(START, "planner")
workflow.add_conditional_edges("planner", should_continue, {
"tools": "tools",
"end": END
})
workflow.add_edge("tools", "planner") # 工具结果返回给planner
memory = MemorySaver()
research_agent = workflow.compile(checkpointer=memory)
# --- 执行 ---
config = {"configurable": {"thread_id": "research-001"}}
result = research_agent.invoke(
{
"messages": [HumanMessage(content="研究2025年大模型Agent技术的最新进展")],
"research_topic": "LLM Agent技术进展",
"iteration": 0
},
config=config
)
for msg in result["messages"]:
if hasattr(msg, "content") and msg.content:
print(f"[{msg.type}]: {msg.content[:200]}")
17.4 CrewAI 框架¶
17.4.1 核心概念: Agent / Task / Crew¶
CrewAI 提供了直观的三层抽象,模拟现实世界的团队协作:
| 概念 | 说明 | 现实类比 |
|---|---|---|
| Agent | 具有角色、目标、背景的智能体 | 团队成员 |
| Task | 需要完成的具体任务 | 工作任务单 |
| Crew | Agent 和 Task 的组合,定义协作模式 | 项目团队 |
"""CrewAI完整示例:市场研究团队"""
# pip install crewai crewai-tools
from crewai import Agent, Task, Crew, Process
from crewai_tools import SerperDevTool, ScrapeWebsiteTool
# --- 工具 ---
search_tool = SerperDevTool()
scrape_tool = ScrapeWebsiteTool()
# --- Agent定义 ---
researcher = Agent(
role="高级市场研究员",
goal="发现{topic}领域的最新趋势和关键数据",
backstory="""你是一位拥有10年经验的市场研究专家,
擅长从海量信息中提取关键洞察。你的分析总是数据驱动且有前瞻性。""",
tools=[search_tool, scrape_tool],
llm="gpt-5-mini",
verbose=True,
max_iter=5, # 最大迭代次数
allow_delegation=True # 允许委托任务给其他Agent
)
analyst = Agent(
role="数据分析师",
goal="基于研究数据进行深度分析,提取可操作的洞察",
backstory="""你是一位专注于科技行业的数据分析师,
擅长定量分析和趋势预测。你的分析报告以准确和深度著称。""",
llm="gpt-5-mini",
verbose=True
)
writer = Agent(
role="商业报告撰写专家",
goal="将研究和分析结果撰写为专业的商业报告",
backstory="""你是一位资深商业写手,擅长将复杂的技术分析
转化为清晰、有洞察力的商业报告。你的报告结构清晰、论据充分。""",
llm="gpt-5-mini",
verbose=True
)
# --- Task定义 ---
research_task = Task(
description="""对{topic}进行全面的市场调研:
1. 当前市场规模和增长趋势
2. 主要玩家和竞争格局
3. 最新技术突破和产品发布
4. 投资和融资动态
请提供详细的数据和来源。""",
expected_output="一份详尽的市场调研报告,包含数据和来源",
agent=researcher
)
analysis_task = Task(
description="""基于市场调研数据进行深度分析:
1. 市场SWOT分析
2. 未来3年趋势预测
3. 关键机会和风险点
4. 对中国市场的专项分析""",
expected_output="专业的数据分析报告,包含图表建议和关键洞察",
agent=analyst,
context=[research_task] # 依赖研究任务的结果
)
report_task = Task(
description="""将研究和分析结果综合为一份专业报告:
1. 执行摘要(200字以内)
2. 市场概况
3. 深度分析
4. 未来趋势与建议
5. 行动建议
报告语言:中文""",
expected_output="一份完整的中文市场分析报告(Markdown格式)",
agent=writer,
context=[research_task, analysis_task],
output_file="market_report.md" # 自动保存到文件
)
# --- Crew定义 ---
crew = Crew(
agents=[researcher, analyst, writer],
tasks=[research_task, analysis_task, report_task],
process=Process.sequential, # 顺序执行
verbose=True
)
# --- 执行 ---
result = crew.kickoff(inputs={"topic": "2025年AI Agent市场"})
print(result)
17.4.2 协作模式¶
# 顺序模式:Task按顺序执行
crew_seq = Crew(
agents=[researcher, analyst, writer],
tasks=[research_task, analysis_task, report_task],
process=Process.sequential
)
# 层级模式:由Manager Agent分配任务
crew_hier = Crew(
agents=[researcher, analyst, writer],
tasks=[research_task, analysis_task, report_task],
process=Process.hierarchical,
manager_llm="gpt-5.4" # 自动创建Manager Agent
)
17.4.3 自定义工具¶
from crewai.tools import BaseTool
from pydantic import BaseModel, Field
class DatabaseQueryInput(BaseModel):
query: str = Field(description="SQL查询语句")
class DatabaseQueryTool(BaseTool):
name: str = "database_query"
description: str = "执行SQL查询获取业务数据"
args_schema: type[BaseModel] = DatabaseQueryInput
def _run(self, query: str) -> str:
# 实现数据库查询逻辑
return f"查询结果:执行 {query} 返回 100 条记录"
# 使用自定义工具
db_tool = DatabaseQueryTool()
analyst_with_db = Agent(
role="数据分析师",
goal="分析业务数据",
backstory="专业数据分析师",
tools=[db_tool],
llm="gpt-5-mini"
)
17.5 Agno¶
17.5.1 核心抽象: Agent / Team / Workflow / AgentOS¶
Agno 是 agno-agi/agno 开源的轻量 Agent 框架。在多 Agent 场景下,它最大的特点不是只提供单个 Agent 类,而是把多智能体协作和服务化放到同一条主线上:
| 抽象 | 作用 | 适合场景 |
|---|---|---|
| Agent | 单个智能体,负责推理、工具调用、记忆 | 搜索 Agent、分析 Agent |
| Team | 多个 Agent 协作,支持协调模式 | researcher + writer + reviewer |
| Workflow | 显式步骤编排 | 深度研究、审批流、报告生成 |
| AgentOS | FastAPI 运行时,可直接服务化 | 内网 API、前后端联调、生产部署 |
和本章其他框架相比:
- 对比 LangGraph:Agno 不把“状态图”作为唯一中心抽象,而是强调
Agent -> Team -> Workflow -> Runtime的统一体验 - 对比 CrewAI:Agno 不只关心角色分工,还把 workflow 编排和 HTTP 服务化一起考虑
- 对比 AutoGen:Agno 不以“群聊式对话”作为主要心智模型,而更偏向结构化协作与运行时交付
按官方当前文档,Agno 还有四个很适合在面试里单独讲清楚的标签:
- 模型无关:官方文档列出 OpenAI / Anthropic / Gemini / Grok / DeepSeek / Ollama 等多家 provider
- 多模态原生:文本、图像、音频、视频走同一套框架能力
- 互操作友好:AgentOS 里可直接暴露 Agent / Team / Workflow API,也支持 A2A 接口
- 生产导向:AgentOS 自带 API、会话、追踪和权限能力,适合从 demo 直接走向服务化
17.5.2 Team 协作示例¶
"""Agno Team 示例:研究员 + 写作者"""
# pip install -U "agno[os]" openai
from agno.agent import Agent
from agno.models.openai import OpenAIResponses
from agno.team import Team
from agno.team.mode import TeamMode
researcher = Agent(
name="Researcher",
role="负责检索信息、整理证据并指出风险点",
model=OpenAIResponses(id="gpt-5-mini"),
instructions=[
"优先整理事实和证据,不要提前下结论。",
"输出时标出关键发现和待确认信息。",
],
)
writer = Agent(
name="Writer",
role="负责把研究结果写成结构清晰的技术说明",
model=OpenAIResponses(id="gpt-5-mini"),
instructions=[
"按背景、结论、证据、建议四部分组织输出。",
"语言简洁,适合工程团队阅读。",
],
)
team = Team(
name="Agent Research Team",
mode=TeamMode.coordinate,
model=OpenAIResponses(id="gpt-5.2"),
members=[researcher, writer],
instructions=[
"先由 Researcher 收集信息,再由 Writer 输出总结。",
"如果事实不足,先指出不确定项,再给建议。",
],
markdown=True,
)
team.print_response(
"总结 Agno、LangGraph、CrewAI 在多 Agent 架构上的差异,并给出选型建议",
stream=True,
)
这个例子体现了 Agno 在多 Agent 场景下的思路:
Agent负责角色能力封装Team负责任务协调mode=TeamMode.coordinate表示由团队层统一编排成员协作
17.5.3 Workflow / AgentOS / A2A 的价值¶
如果你的需求不只是“多个 Agent 轮流说话”,而是:
- 要把任务拆成稳定步骤
- 要把同一套逻辑暴露成 HTTP 服务
- 要在后续接前端、网关、监控和数据库
那 Agno 的 Workflow + AgentOS 路线会很有吸引力。官方 Workflows 文档把 Agent、Team、函数都视为可编排 step;官方 AgentOS 文档则明确给出 POST /agents/{id}/runs、POST /teams/{id}/runs、POST /workflows/{id}/runs 三类统一接口。
"""Agno Workflow + AgentOS 示例"""
from agno.agent import Agent
from agno.models.openai import OpenAIResponses
from agno.os import AgentOS
from agno.team import Team
from agno.team.mode import TeamMode
from agno.workflow import Step, Workflow
researcher = Agent(
name="Researcher",
model=OpenAIResponses(id="gpt-5-mini"),
instructions="收集事实、证据和来源,避免过早下结论。",
)
writer = Agent(
name="Writer",
model=OpenAIResponses(id="gpt-5-mini"),
instructions="把研究结果整理成结构化说明,突出证据链。",
)
reviewer = Agent(
name="Reviewer",
model=OpenAIResponses(id="gpt-5-mini"),
instructions="检查结论是否有证据支持,指出风险和缺口。",
)
research_team = Team(
id="agno-research-team",
name="Agno Research Team",
members=[researcher, writer],
mode=TeamMode.coordinate,
model=OpenAIResponses(id="gpt-5.2"),
instructions="先研究,再写作,最后交给 reviewer 审查。",
)
research_workflow = Workflow(
id="agno-research-workflow",
name="Agno Research Workflow",
steps=[
Step(name="Research Phase", team=research_team),
Step(name="Review Phase", agent=reviewer),
],
)
research_workflow.print_response(
"对比 LangGraph、Agno、CrewAI 的多 Agent 适用场景,并输出架构建议",
markdown=True,
)
agent_os = AgentOS(
teams=[research_team],
workflows=[research_workflow],
tracing=True,
a2a_interface=True,
)
app = agent_os.get_app()
# 本地调试:
# fastapi dev agno_team_app.py
这段代码里有三个要点:
Team解决“多人怎么协作”Workflow解决“步骤怎么稳定复用”AgentOS解决“怎么把 team / workflow 暴露成 API 与 A2A 端点”
这也是 Agno 和 CrewAI 的一个明显差异:
CrewAI 更强调“团队协作抽象”,而 Agno 更强调“团队协作 + workflow + runtime 一体化”。
17.6 AutoGen ( Microsoft )¶
17.6.1 核心架构¶
AutoGen 是微软开源的多 Agent 对话框架,核心特点是通过 Agent 对话实现协作。
⚠️ 状态说明(2026-03-26 复核):Microsoft 官方 AutoGen stable 文档仍然存在,且 0.2 页面明确指向 0.4/stable 文档。与此同时,Microsoft 当前统一新路线已经转向 Microsoft Agent Framework;截至 2026-03,Microsoft 官方 Learn 已提供 Agent Framework 概览,Foundry Blog 已发布 Release Candidate 公告。另有一个社区项目 AG2 源自 AutoGen,但它不等同于 Microsoft 官方 AutoGen 0.4/stable。
"""AutoGen经典用法(0.2.x)"""
# pip install pyautogen
import autogen
# 配置LLM
config_list = [
{
"model": "gpt-5-mini",
"api_key": "your-api-key"
}
]
llm_config = {"config_list": config_list, "temperature": 0}
# AssistantAgent:AI助手
assistant = autogen.AssistantAgent(
name="assistant",
llm_config=llm_config,
system_message="""你是一个Python编程专家。
编写代码时请确保代码完整可运行。"""
)
# UserProxyAgent:用户代理(可自动执行代码)
user_proxy = autogen.UserProxyAgent(
name="user_proxy",
human_input_mode="NEVER", # NEVER/ALWAYS/TERMINATE
max_consecutive_auto_reply=5,
is_termination_msg=lambda x: "TERMINATE" in x.get("content", ""),
code_execution_config={
"work_dir": "coding",
"use_docker": False # 生产环境建议True
}
)
# 发起对话
user_proxy.initiate_chat(
assistant,
message="用Python写一个函数,计算斐波那契数列的前N项,并绘制折线图。"
)
17.6.2 多 Agent 对话模式¶
"""AutoGen Group Chat"""
import autogen
config_list = [{"model": "gpt-5-mini", "api_key": "your-api-key"}]
llm_config = {"config_list": config_list}
# 定义多个Agent
coder = autogen.AssistantAgent(
name="Coder",
llm_config=llm_config,
system_message="你是一个Python编程专家,负责编写代码。"
)
reviewer = autogen.AssistantAgent(
name="Reviewer",
llm_config=llm_config,
system_message="""你是一个代码审查专家,负责审查代码质量。
审查通过时回复"APPROVE",否则给出修改建议。"""
)
tester = autogen.AssistantAgent(
name="Tester",
llm_config=llm_config,
system_message="你是一个测试工程师,负责为代码编写测试用例。"
)
user_proxy = autogen.UserProxyAgent(
name="Admin",
human_input_mode="NEVER",
code_execution_config={"work_dir": "coding", "use_docker": False},
is_termination_msg=lambda x: "APPROVE" in x.get("content", "")
)
# Group Chat:多Agent群聊
group_chat = autogen.GroupChat(
agents=[user_proxy, coder, reviewer, tester],
messages=[],
max_round=12,
speaker_selection_method="auto" # auto/round_robin/random/manual
)
manager = autogen.GroupChatManager(
groupchat=group_chat,
llm_config=llm_config
)
# 发起群聊
user_proxy.initiate_chat(
manager,
message="开发一个命令行待办事项管理工具,支持增删改查和优先级排序。"
)
17.6.3 AutoGen 0.4+ 新架构(官方重构版)¶
"""AutoGen 0.4+ 新架构示例"""
# pip install autogen-agentchat autogen-ext
from autogen_agentchat.agents import AssistantAgent
from autogen_agentchat.teams import RoundRobinGroupChat
from autogen_agentchat.conditions import TextMentionTermination
from autogen_ext.models.openai import OpenAIChatCompletionClient
# 创建模型客户端
model_client = OpenAIChatCompletionClient(model="gpt-5-mini")
# 创建Agent
research_agent = AssistantAgent(
name="researcher",
model_client=model_client,
system_message="你是一个研究助手,负责搜索和整理信息。"
)
writing_agent = AssistantAgent(
name="writer",
model_client=model_client,
system_message="你是一个写作助手,负责撰写内容。完成后回复 TERMINATE。"
)
# 终止条件
termination = TextMentionTermination("TERMINATE")
# 创建团队
team = RoundRobinGroupChat(
participants=[research_agent, writing_agent],
termination_condition=termination,
max_turns=6
)
# 异步执行
import asyncio # Python标准异步库
async def main():
result = await team.run(task="研究并撰写一篇关于LLM Agent的短文") # await等待异步操作完成
print(result)
asyncio.run(main()) # 创建事件循环运行顶层协程
17.7 框架对比¶
17.7.1 综合对比表¶
| 维度 | LangGraph | Agno | CrewAI | AutoGen | Dify |
|---|---|---|---|---|---|
| 定位 | 底层编排框架 | 多 Agent + Workflow + Runtime 一体化 | 高层协作框架 | 多 Agent 对话框架 | 低代码平台 |
| 抽象级别 | 低(图/节点/边) | 中高( Agent/Team/Workflow/AgentOS ) | 高( Agent/Task/Crew ) | 中( Agent/Chat ) | 极高(可视化拖拽) |
| 灵活性 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ |
| 易用性 | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 生产就绪 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| 状态管理 | 内置 Checkpoint | Team/Workflow + DB/会话管理 | 有限 | 对话历史 | 内置 |
| 流式输出 | 原生支持 | 原生支持 | 有限支持 | 有限支持 | 原生支持 |
| 服务化运行时 | 需自行接 Web 框架 | AgentOS 原生提供 | 需自行封装 | 需自行封装 | 平台原生 |
| A2A / MCP 互操作 | MCP 易接入,A2A 需自定义 | AgentOS 原生支持 A2A,MCP 也是一等能力 | 以工具接入为主 | 以对话/代码执行为主 | 平台内置 |
| Human-in-loop | 原生支持 | 可通过运行时与 workflow 设计接入 | 有限 | 支持 | 支持 |
| 适合场景 | 复杂工作流、生产系统 | 需要统一开发、协作、服务化的 Agent 系统 | 快速原型、团队协作 | 代码生成、多 Agent 对话 | 非技术用户、快速部署 |
| 学习曲线 | 较陡 | 中等 | 平缓 | 中等 | 极低 |
17.7.2 选型建议¶
需要精细控制工作流? → LangGraph
想统一 Agent + Team + API? → Agno
快速搭建多Agent原型? → CrewAI
多Agent对话 + 代码执行? → AutoGen
非技术人员 / 快速上线? → Dify
已有LangChain生态? → LangGraph(无缝集成)
📋 面试要点¶
高频面试题¶
Q1: 什么时候需要多 Agent 系统?单 Agent 有什么局限?
答:当任务涉及多角色分工(如研究→分析→写作)、需要不同工具集、推理链过长容易出错、或需要自我审查时,多 Agent 系统优于单 Agent 。单 Agent 局限包括:上下文窗口限制、角色混乱、工具过多选择困难、缺乏自我纠错能力。
Q2: 解释 LangGraph 的 StateGraph 核心概念?
答: StateGraph 基于有向图模型:①State 是全局状态对象,在节点间流转;②Node 是执行函数,接收 state 返回更新;③Edge 是节点连接关系;④Conditional Edge 根据 state 动态决定路由。关键特性还包括 Checkpoint 持久化和 Human-in-the-loop 支持。
Q3: ReAct 和 Plan-and-Execute 模式的区别?
答: ReAct 是交替的推理-行动循环( Thought→Action→Observation ),适合需要实时信息的任务。 Plan-and-Execute 先生成完整计划再逐步执行,适合多步骤复杂任务。 ReAct 更灵活但可能发散, Plan-and-Execute 更有条理但适应性较差。实际项目中常结合使用。
Q4: CrewAI 的 Agent/Task/Crew 分别是什么?
答: Agent 是具有角色(role)、目标(goal)、背景(backstory)的智能体; Task 是具体任务,包含描述和期望输出,绑定到特定 Agent ; Crew 是 Agent 和 Task 的组合,定义执行流程( sequential/hierarchical )。这种三层抽象模拟了现实世界的团队协作。
Q5: 如何在 LangGraph 中实现 Human-in-the-Loop ?
答:通过 compile 时设置
interrupt_before或interrupt_after参数指定暂停节点,配合 Checkpointer 持久化状态。图在指定节点前/后暂停,返回当前状态供人类审查。人类决策后通过invoke恢复执行。这需要 Checkpoint 支持( MemorySaver 或持久化存储)。
Q6: Agno 和 CrewAI 的差异是什么?
答:两者都适合多 Agent 协作,但侧重点不同。 CrewAI 更强调
Agent / Task / Crew的角色分工和团队协作心智模型,适合快速做出“多人分工”的原型; Agno 则把Agent / Team / Workflow / AgentOS放进同一套框架里,更适合后续还要做服务化、接入多模态输入、统一管理运行时的项目。
Q7: Agno 里 Team 和 Workflow 应该怎么分工?
答: Team 适合“问题开放、需要动态协作”的场景,团队 leader 可以根据任务临时决定委托给谁; Workflow 适合“步骤稳定、需要可重复执行”的场景,开发者提前定义好 research → review → report 这类固定流程。很多生产系统会把 Team 作为 Workflow 的某一个 step 来组合使用。
✏️ 练习¶
练习 1 : ReAct Agent¶
使用 LangChain 和 LangGraph 实现一个 ReAct Agent ,能够使用天气查询和计算器工具回答问题。
💡 参考答案
"""练习1参考答案:ReAct Agent(天气+计算器)"""
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import create_react_agent
from langchain_core.tools import tool
@tool
def get_weather(city: str) -> str:
"""查询指定城市的天气信息"""
# 实际项目中接入天气API(如和风天气/OpenWeatherMap)
weather_data = {
"北京": "晴天,气温 22°C,空气质量良好",
"上海": "多云,气温 25°C,有轻微雾霾",
"深圳": "阵雨,气温 28°C,湿度 85%",
}
return weather_data.get(city, f"未找到{city}的天气数据,请检查城市名称")
@tool
def calculator(expression: str) -> str:
"""计算数学表达式(支持加减乘除和幂运算)"""
import ast
try:
tree = ast.parse(expression, mode='eval')
for node in ast.walk(tree):
if not isinstance(node, (ast.Expression, ast.BinOp, ast.UnaryOp,
ast.Constant, ast.Add, ast.Sub, ast.Mult,
ast.Div, ast.Mod, ast.Pow, ast.USub)):
return "错误:不允许的表达式"
result = eval(compile(tree, '<expr>', 'eval'), {"__builtins__": {}}, {})
return f"{expression} = {result}"
except Exception as e:
return f"计算错误: {e}"
# 创建 ReAct Agent
llm = ChatOpenAI(model="gpt-5-mini", temperature=0)
agent = create_react_agent(model=llm, tools=[get_weather, calculator])
# 测试
result = agent.invoke({
"messages": [{"role": "user", "content": "北京和上海今天的天气如何?两地的温差是多少度?"}]
})
print(result["messages"][-1].content)
练习 2 : LangGraph 研究工作流¶
基于 LangGraph 构建一个"研究-写作-审核"三节点工作流,包含条件边(审核不通过则返回写作节点)。
💡 参考答案
"""练习2参考答案:研究-写作-审核工作流"""
from typing import TypedDict, Annotated, Literal
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage
class WorkflowState(TypedDict):
messages: Annotated[list, add_messages]
topic: str
iteration: int
approved: bool
llm = ChatOpenAI(model="gpt-5-mini", temperature=0)
def researcher(state: WorkflowState) -> dict:
"""研究节点:收集信息"""
response = llm.invoke([
SystemMessage(content="你是一个研究助手。请收集关于给定主题的关键信息,列出要点。"),
HumanMessage(content=f"请研究以下主题并整理要点:{state['topic']}")
])
return {"messages": [response]}
def writer(state: WorkflowState) -> dict:
"""写作节点:基于研究结果撰写文章"""
research = state["messages"][-1].content
response = llm.invoke([
SystemMessage(content="你是一个技术写作专家。基于研究要点撰写一篇结构清晰的技术摘要。"),
HumanMessage(content=f"基于以下研究要点撰写技术摘要:\n{research}")
])
return {"messages": [response], "iteration": state.get("iteration", 0) + 1}
def reviewer(state: WorkflowState) -> dict:
"""审核节点:检查文章质量"""
article = state["messages"][-1].content
response = llm.invoke([
SystemMessage(content="""你是质量审核专家。审核文章质量:
1. 内容是否准确完整
2. 结构是否清晰
3. 语言是否流畅
如果质量合格,回复"APPROVED";否则回复"REVISE"并说明问题。"""),
HumanMessage(content=f"请审核以下文章:\n{article}")
])
approved = "APPROVED" in response.content
return {"messages": [response], "approved": approved}
def should_revise(state: WorkflowState) -> Literal["revise", "end"]:
"""条件边:审核不通过则返回写作节点"""
if state.get("approved", False) or state.get("iteration", 0) >= 3:
return "end"
return "revise"
# 构建工作流
graph = StateGraph(WorkflowState)
graph.add_node("researcher", researcher)
graph.add_node("writer", writer)
graph.add_node("reviewer", reviewer)
graph.add_edge(START, "researcher")
graph.add_edge("researcher", "writer")
graph.add_edge("writer", "reviewer")
graph.add_conditional_edges("reviewer", should_revise, {
"revise": "writer",
"end": END
})
app = graph.compile()
# 执行
result = app.invoke({
"messages": [],
"topic": "2025年大模型Agent技术趋势",
"iteration": 0,
"approved": False
})
print(result["messages"][-1].content)
练习 3 : CrewAI 团队¶
使用 CrewAI 创建一个 3-Agent 团队(产品经理、开发者、测试工程师),完成一个简单应用的需求分析→开发→测试流程。
💡 参考答案
"""练习3参考答案:CrewAI 3-Agent团队"""
from crewai import Agent, Task, Crew, Process
# 定义3个Agent
pm = Agent(
role="产品经理",
goal="分析需求并输出清晰的产品需求文档",
backstory="你是一位经验丰富的产品经理,擅长需求分析和用户故事编写。",
llm="gpt-5-mini",
verbose=True,
)
developer = Agent(
role="Python开发者",
goal="根据需求文档编写高质量的Python代码",
backstory="你是一位资深Python开发者,代码风格清晰、注重可测试性。",
llm="gpt-5-mini",
verbose=True,
)
tester = Agent(
role="测试工程师",
goal="为代码编写完整的单元测试,确保功能正确",
backstory="你是一位严谨的测试工程师,擅长边界条件分析和pytest测试编写。",
llm="gpt-5-mini",
verbose=True,
)
# 定义3个Task
requirement_task = Task(
description="分析以下需求并输出PRD文档:开发一个命令行TODO管理工具,支持添加、删除、列出、标记完成功能。输出应包含功能列表、数据结构设计和接口定义。",
expected_output="一份Markdown格式的PRD文档,包含功能列表、数据结构、接口定义",
agent=pm,
)
dev_task = Task(
description="根据PRD文档,用Python实现TODO管理工具。要求:使用dataclass定义数据结构,实现TodoManager类,代码有类型注解和docstring。",
expected_output="完整的Python代码,包含TodoManager类和所有方法实现",
agent=developer,
context=[requirement_task],
)
test_task = Task(
description="为TodoManager类编写pytest单元测试。覆盖:添加TODO、删除TODO、列出TODO、标记完成、边界情况(空列表删除、重复ID等)。",
expected_output="完整的pytest测试文件,包含至少8个测试用例",
agent=tester,
context=[dev_task],
)
# 组建Crew并执行
crew = Crew(
agents=[pm, developer, tester],
tasks=[requirement_task, dev_task, test_task],
process=Process.sequential,
verbose=True,
)
result = crew.kickoff()
print(result)
练习 4 :框架选型¶
针对以下场景,分析应选择哪个框架并说明理由: - 场景 A :构建一个客服系统,需要精细的对话流程控制 - 场景 B :快速搭建一个内容创作团队原型 - 场景 C :构建一个能自动编写和测试代码的系统 - 场景 D :需要把多 Agent 协作快速封装成 HTTP 服务,供前端直接调用
💡 参考答案
**场景 A:LangGraph** - 客服系统需要精细的对话状态管理(等待用户输入、转人工、多轮上下文) - LangGraph 的 StateGraph + Conditional Edge 天然适合对话流程控制 - Checkpoint 支持会话持久化,Human-in-the-Loop 支持转人工 - 生产就绪度高,可配合 LangSmith 做可观测性 **场景 B:CrewAI** - 内容创作团队是典型的"角色分工"场景(研究员→分析师→写手) - CrewAI 的 Agent/Task/Crew 三层抽象最贴合"团队协作"心智模型 - 代码量最少,快速出原型 - `Process.sequential` 直接对应"研究→分析→写作"流程 **场景 C:AutoGen** - 代码编写和测试天然适合"多 Agent 对话"模式(Coder ↔ Reviewer ↔ Tester) - AutoGen 的 `UserProxyAgent` 支持自动代码执行和验证 - GroupChat 模式让多个 Agent 围绕代码质量进行多轮讨论 - 内置代码执行沙箱,安全运行生成的代码 **场景 D:Agno** - 需要把 Agent 协作直接暴露为 HTTP API,Agno 的 AgentOS 是最佳选择 - `AgentOS` 自带 FastAPI 运行时,`POST /teams/{id}/runs` 开箱即用 - 原生支持 A2A 接口,便于与其他系统集成 - Team + Workflow 组合可以灵活编排 Agent 协作逻辑📝 本章小结¶
本章系统介绍了多 Agent 框架的核心内容:
- ✅ 多 Agent 系统概述:核心动机、架构模式(顺序/层级/协作/竞争)
- ✅ Agent 设计模式:ReAct、Plan-and-Execute、Reflection、Multi-Agent Collaboration
- ✅ LangGraph 深入教程:StateGraph、工作流编排、Checkpointing、子图、流式输出
- ✅ CrewAI 框架:Agent/Task/Crew 三层抽象、协作模式、自定义工具
- ✅ Agno 框架:Agent/Team/Workflow/AgentOS 四层抽象、Team 协作、Workflow 编排
- ✅ AutoGen:经典用法、Group Chat、0.4+ 新架构
- ✅ 框架对比与选型:LangGraph vs Agno vs CrewAI vs AutoGen vs Dify
- ✅ 练习题:ReAct Agent、LangGraph 工作流、CrewAI 团队、框架选型分析
通过本章学习,你应该能够: - 理解多 Agent 系统的核心动机与设计原则 - 掌握 ReAct、Plan-and-Execute、Reflection 等 Agent 设计模式 - 使用 LangGraph 构建复杂的有状态工作流 - 使用 CrewAI 快速搭建多 Agent 协作原型 - 了解 Agno 的 Team/Workflow/AgentOS 一体化方案 - 根据场景选择合适的多 Agent 框架 - 准备好应对大厂面试
🔗 下一步¶
下一章我们将深入学习高级 RAG 技术,掌握检索增强生成的进阶策略。
继续学习: 18-高级RAG技术.md
💡 思考题¶
-
什么时候需要多 Agent 系统?单 Agent 有什么局限?
当任务涉及多角色分工(如研究→分析→写作)、需要不同工具集、推理链过长容易出错、或需要自我审查时,多 Agent 系统优于单 Agent。单 Agent 局限包括:上下文窗口限制、角色混乱、工具过多选择困难、缺乏自我纠错能力。
-
LangGraph 的 StateGraph 核心概念是什么?
StateGraph 基于有向图模型:①State 是全局状态对象,在节点间流转;②Node 是执行函数,接收 state 返回更新;③Edge 是节点连接关系;④Conditional Edge 根据 state 动态决定路由。关键特性还包括 Checkpoint 持久化和 Human-in-the-loop 支持。
-
ReAct 和 Plan-and-Execute 模式的区别是什么?
ReAct 是交替的推理-行动循环(Thought→Action→Observation),适合需要实时信息的任务。Plan-and-Execute 先生成完整计划再逐步执行,适合多步骤复杂任务。ReAct 更灵活但可能发散,Plan-and-Execute 更有条理但适应性较差。实际项目中常结合使用。
-
CrewAI 和 Agno 的核心差异是什么?
CrewAI 更强调 Agent/Task/Crew 的角色分工和团队协作心智模型,适合快速做出"多人分工"的原型;Agno 则把 Agent/Team/Workflow/AgentOS 放进同一套框架里,更适合后续还要做服务化、接入多模态输入、统一管理运行时的项目。
-
在实际项目中如何选择多 Agent 框架?
需要精细控制工作流→LangGraph;想统一 Agent+Team+API→Agno;快速搭建多 Agent 原型→CrewAI;多 Agent 对话+代码执行→AutoGen;非技术人员/快速上线→Dify。选择时还需考虑:团队技术栈、生产就绪度、社区生态、可观测性需求。
📚 参考资料 - LangGraph 官方文档 - Agno 官方文档 - Agno Teams Overview - Agno Workflows Overview - Agno GitHub - CrewAI 官方文档 - AutoGen 官方文档 - Microsoft Agent Framework Overview - 论文:"AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation" (2023) - 论文:"ReAct: Synergizing Reasoning and Acting in Language Models" (2023) - 论文:"Reflexion: Language Agents with Verbal Reinforcement Learning" (2023)
最后更新日期: 2026-03-27 适用版本: LangGraph / Agno / CrewAI / AutoGen / Microsoft Agent Framework(以各官方 stable/docs 页面为准)
⚠️ 注意:本章部分示例使用了旧版 LangChain API(
AgentExecutor),推荐使用 LangGraph 的create_react_agent。最新的 LangGraph/CrewAI/AutoGen 示例请参考: - AI Agent开发实战/02-主流Agent框架 - 框架版本更新说明-2026年3月