12-可观测性、告警分级与值班 Runbook¶
目标:把 SLO 文档变成可执行的日常运维动作,而不是只停留在指标定义上。
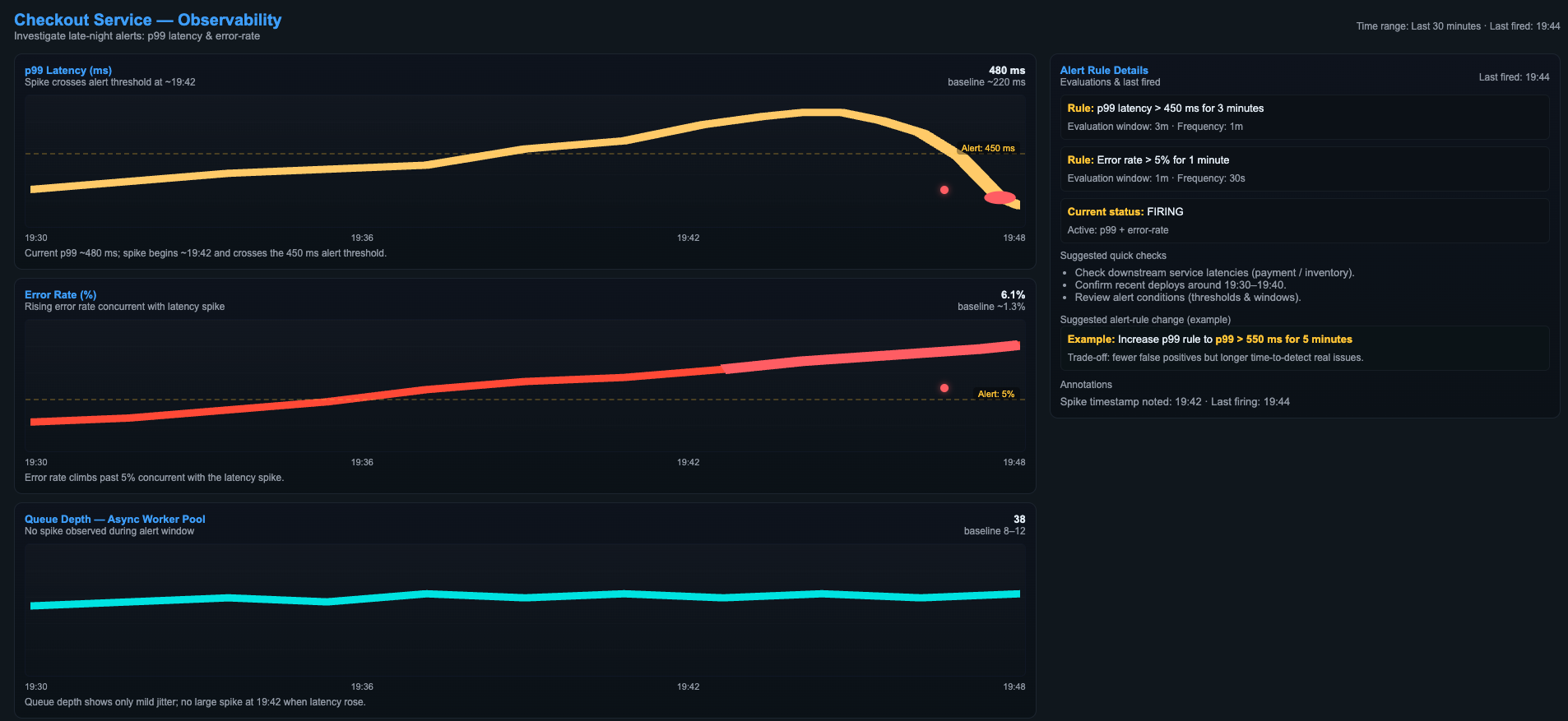
图源:Wikimedia Commons - Observability dashboard.png,CC0。当前主图是一张公开发布的 observability dashboard 示意图,用于说明值班定位时应优先查看的核心看板结构。
{kind=link}
一、为什么 AI 系统更需要可观测性¶
AI 服务和普通 API 不一样,很多时候系统还活着,但用户已经感知到“服务坏了”:
- 引用消失了
- 工具调用变慢了
- Agent 开始反复兜圈
- 成本突然飙升
- 模型没有报错,但输出质量明显变差
所以可观测性不能只看 CPU / 内存 / 5xx。至少要做到:
- 用户层有结果质量视角
- 系统层有延迟、错误和依赖视角
- 资源层能追 GPU、缓存、队列和成本
二、AI 系统最少要有三层看板¶
| 层级 | 重点指标 | 你在回答什么问题 |
|---|---|---|
| 用户 / 业务层 | 成功率、任务完成率、错答率、投诉率 | 用户是不是已经感知到服务变差 |
| 系统层 | 可用性、P95/P99、超时率、依赖失败率 | 哪条链路正在坏 |
| 资源 / 成本层 | GPU/CPU、内存、缓存命中率、单请求成本、队列深度 | 为什么会坏,代价有多大 |
如果是 RAG / Agent,还应额外补:
- 引用覆盖率
- Faithfulness
- 工具调用成功率
- 错误循环率
三、告警分级怎么设计¶
告警分级的核心不是“颜色好不好看”,而是值班同学拿到告警后知道该不该立刻停下手头一切。
| 级别 | 典型触发条件 | 处理要求 |
|---|---|---|
P0 | 服务不可用、危险动作误执行、核心链路大面积失败 | 立即响应,必要时直接回滚 |
P1 | P99 明显恶化、质量显著下降、成本异常飙升 | 30 分钟内定位并止血 |
P2 | 单节点抖动、局部 bad case 上升、资源逼近上限 | 排期处理并持续观察 |
告警规则至少要回答:
- 触发阈值是什么
- 连续多久才算真的触发
- 由谁值班接手
- 接手后的前 5 分钟先做什么
四、一份最小可用的值班 Runbook¶
Markdown
# On-call Runbook
## 1. 首先确认
- 当前事故等级:
- 影响范围:
- 是否需要拉群:
## 2. 先看哪些指标
- 可用性:
- 延迟:
- 错误率:
- 质量指标:
- 资源指标:
## 3. 常见处置动作
- 限流:
- 降级:
- 关闭实验:
- 回滚版本:
## 4. 何时升级
- 达到 P0:
- 持续时间超过:
- 波及范围超过:
值班 Runbook 的价值在于:新人也能按固定顺序处理,而不是临场凭感觉。
五、你应该把哪些内容补到项目里¶
如果你想把自己的项目讲得更像生产系统,建议至少补这几样:
- 一张核心看板截图或字段说明
- 一份告警分级表
- 一份最小 Runbook
- 一条“什么情况下立刻回滚”的硬规则
- 一套质量指标和系统指标联动的说明
这几样东西会明显提升“你真的做过线上系统”的可信度。
六、面试里怎么回答¶
推荐结构:
- 先讲三层看板:用户、系统、资源
- 再讲告警分级:P0 / P1 / P2
- 补 Runbook:值班先看什么、先做什么
- 最后说明哪些动作会触发降级或回滚
可以直接这样说:
Text Only
我会把 AI 服务的可观测性拆成三层:
用户层看成功率、错答率和任务完成率;
系统层看可用性、延迟、错误率和依赖状态;
资源层看 GPU、缓存、队列和成本。
告警不会只写一个阈值,我会同时定义连续时间、责任人和处置步骤,
并把最常见的限流、降级和回滚动作写进 Runbook,
保证值班同学在压力下也能按固定顺序执行。
七、自检清单¶
- 我知道 AI 服务最少要看用户、系统、资源三层指标
- 我能给出一份 P0 / P1 / P2 告警分级示例
- 我有一份最小可用的值班 Runbook
- 我知道哪些指标会触发降级、熔断或回滚
- 我能把“质量问题”纳入可观测性,而不只盯基础设施
结论¶
可观测性不是“有几个图表”就算完成,而是要把指标、告警、值班动作和回滚纪律连成一条闭环。
对 AI 系统来说,谁能把这条闭环讲清楚,谁就更像真正做过线上系统的人。
⚠️ 核验说明(2026-03-29):本页已重新复核图片来源与值班流程表述。若你的团队已采用固定告警等级或值班规范,请以团队标准为准。
最后更新日期: 2026-03-29