📊 概率统计基础¶
难度:⭐⭐⭐⭐ | 预计学习时间:8-10小时 | 重要性:AI面试必考
🎯 学习目标¶
- 掌握贝叶斯定理及其在ML中的应用
- 理解MLE/MAP的数学推导
- 掌握EM算法原理并实现GMM
- 深刻理解KL散度与交叉熵的联系
1. 概率论基础¶
1.1 条件概率与贝叶斯¶
import numpy as np
# 经典例子:疾病检测
# 疾病发病率1%,检测准确率99%,假阳性率2%
# 检测阳性时,真的有病的概率?
P_disease = 0.01
P_positive_given_disease = 0.99 # 灵敏度
P_positive_given_healthy = 0.02 # 假阳性率
# 贝叶斯公式
P_positive = P_positive_given_disease * P_disease + \
P_positive_given_healthy * (1 - P_disease)
P_disease_given_positive = P_positive_given_disease * P_disease / P_positive
print(f"检测阳性时,实际有病概率: {P_disease_given_positive:.4f}")
# ≈ 0.3333 — 只有33%!这就是贝叶斯的反直觉之处
1.2 常见概率分布¶

| 分布 | 概率密度/质量 | 均值 | 方差 | AI应用 |
|---|---|---|---|---|
| 伯努利 \(B(p)\) | \(p^k(1-p)^{1-k}\) | \(p\) | \(p(1-p)\) | 二分类 |
| 高斯 \(N(\mu,\sigma^2)\) | \(\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(x-\mu)^2}{2\sigma^2}}\) | \(\mu\) | \(\sigma^2\) | 到处都是 |
| 多项式 | \(\frac{n!}{\prod k_i!}\prod p_i^{k_i}\) | \(np_i\) | \(np_i(1-p_i)\) | 多分类 |
| Softmax/Gibbs | \(\frac{e^{z_i}}{\sum_j e^{z_j}}\) | — | — | 分类输出 |
import matplotlib.pyplot as plt
from scipy import stats
fig, axes = plt.subplots(1, 3, figsize=(15, 4))
x = np.linspace(-5, 5, 200)
# 高斯分布族
for mu, sigma in [(0, 1), (0, 2), (2, 0.5)]:
axes[0].plot(x, stats.norm.pdf(x, mu, sigma),
label=f'μ={mu}, σ={sigma}')
axes[0].legend(); axes[0].set_title("高斯分布")
# Beta分布(贝叶斯先验)
x_beta = np.linspace(0, 1, 200)
for a, b in [(1, 1), (5, 2), (2, 5), (0.5, 0.5)]:
axes[1].plot(x_beta, stats.beta.pdf(x_beta, a, b),
label=f'α={a}, β={b}')
axes[1].legend(); axes[1].set_title("Beta分布(贝叶斯先验)")
# 泊松分布
x_pois = np.arange(0, 20)
for lam in [1, 4, 10]:
axes[2].bar(x_pois + lam*0.1, stats.poisson.pmf(x_pois, lam),
width=0.3, alpha=0.7, label=f'λ={lam}')
axes[2].legend(); axes[2].set_title("泊松分布")
plt.tight_layout(); plt.show()
2. 极大似然估计(MLE)¶
2.1 原理¶
给定数据 \(X = \{x_1, ..., x_n\}\),找参数 \(\theta\) 使似然函数最大:
2.2 高斯分布MLE推导¶
对 \(\mu\) 求导并令其为0:
对 \(\sigma^2\) 求导并令其为0:
(有偏样本方差,注意使用 \(1/n\) 而非无偏估计的 \(1/(n-1)\))
# 手写高斯MLE
def gaussian_mle(data):
mu_hat = np.mean(data)
sigma2_hat = np.mean((data - mu_hat) ** 2)
return mu_hat, sigma2_hat
data = np.random.normal(loc=5, scale=2, size=1000)
mu, sigma2 = gaussian_mle(data)
print(f"MLE估计: μ={mu:.4f}, σ²={sigma2:.4f}")
print(f"真实值: μ=5.0000, σ²=4.0000")
2.3 MLE vs MAP¶
| 特性 | MLE | MAP |
|---|---|---|
| 公式 | \(\arg\max p(X \mid \theta)\) | \(\arg\max p(X \mid \theta)p(\theta)\) |
| 先验 | 不使用 | 使用先验 \(p(\theta)\) |
| 正则化 | 无 | 先验 = 正则化 |
| L2正则 | — | 高斯先验 \(\Rightarrow\) L2正则 |
| 稀疏解 | — | 拉普拉斯先验 \(\Rightarrow\) L1正则 |
3. EM算法¶
3.1 原理¶
当存在隐变量 \(Z\) 时,直接最大化 \(\log p(X|\theta)\) 困难,EM交替执行:
- E步:计算隐变量后验 \(Q(Z) = p(Z|X, \theta^{(t)})\)
- M步:最大化期望完全对数似然 \(\theta^{(t+1)} = \arg\max_\theta E_Q[\log p(X, Z|\theta)]\)
3.2 GMM-EM实现¶
class GaussianMixtureEM:
"""手写高斯混合模型EM算法"""
def __init__(self, n_components=3, max_iter=100, tol=1e-6): # __init__构造方法,创建对象时自动调用
self.K = n_components
self.max_iter = max_iter
self.tol = tol
def fit(self, X):
n, d = X.shape
# 初始化参数
self.weights = np.ones(self.K) / self.K # π_k
self.means = X[np.random.choice(n, self.K, replace=False)]
self.covs = [np.eye(d) for _ in range(self.K)] # 列表推导式,简洁创建列表
log_likelihood_old = -np.inf
for iteration in range(self.max_iter):
# === E步:计算责任度 γ(z_nk) ===
responsibilities = np.zeros((n, self.K))
for k in range(self.K):
responsibilities[:, k] = self.weights[k] * \
self._gaussian_pdf(X, self.means[k], self.covs[k])
responsibilities /= responsibilities.sum(axis=1, keepdims=True)
# === M步:更新参数 ===
N_k = responsibilities.sum(axis=0) # 每个分量的有效样本数
for k in range(self.K):
# 更新均值
self.means[k] = (responsibilities[:, k:k+1].T @ X) / N_k[k]
# 更新协方差
diff = X - self.means[k]
self.covs[k] = (responsibilities[:, k:k+1] * diff).T @ diff / N_k[k]
self.covs[k] += 1e-6 * np.eye(d) # 数值稳定
# 更新权重
self.weights = N_k / n
# 检查收敛
log_likelihood = np.sum(np.log(
sum(self.weights[k] * self._gaussian_pdf(X, self.means[k], self.covs[k])
for k in range(self.K))))
if abs(log_likelihood - log_likelihood_old) < self.tol:
print(f"EM在第{iteration}轮收敛")
break
log_likelihood_old = log_likelihood
def _gaussian_pdf(self, X, mean, cov):
d = X.shape[1]
diff = X - mean
inv_cov = np.linalg.inv(cov) # np.linalg线性代数运算
exponent = -0.5 * np.sum(diff @ inv_cov * diff, axis=1)
norm = 1 / np.sqrt((2*np.pi)**d * np.linalg.det(cov))
return norm * np.exp(exponent)
# 测试
np.random.seed(42)
X = np.vstack([
np.random.randn(100, 2) + [0, 0],
np.random.randn(100, 2) + [5, 5],
np.random.randn(100, 2) + [0, 5],
])
gmm = GaussianMixtureEM(n_components=3)
gmm.fit(X)
print(f"估计的均值:\n{gmm.means}")
print(f"估计的权重: {gmm.weights}")
4. 信息论基础¶

4.1 熵¶
熵 = 不确定性 = 最优编码的平均码长
def entropy(probs):
"""计算离散分布的熵"""
probs = np.array(probs) # np.array创建NumPy数组
probs = probs[probs > 0] # 避免log(0)
return -np.sum(probs * np.log(probs))
# 公平硬币 vs 不公平硬币
print(f"公平硬币熵: {entropy([0.5, 0.5]):.4f} nats") # 0.6931
print(f"偏硬币熵: {entropy([0.9, 0.1]):.4f} nats") # 0.325
print(f"确定事件熵: {entropy([1.0, 0.0]):.4f} nats") # 0.0
4.2 KL散度¶
关键性质: - \(D_{KL} \geq 0\)(Gibbs不等式 / 信息不等式) - \(D_{KL}(P \| Q) \neq D_{KL}(Q \| P)\)(不对称!面试必考) - \(D_{KL} = 0 \iff P = Q\)
KL散度非负性证明(Jensen不等式应用):
因为 \(\log\) 是严格凹函数,由Jensen不等式(凹函数版本:\(E[f(X)] \leq f(E[X])\)),有:
因此 \(D_{KL}(P \| Q) \geq 0\)。等号成立当且仅当 \(\frac{Q(x)}{P(x)}\) 为常数(Jensen不等式对严格凹函数取等条件),即 \(P = Q\)。
4.3 交叉熵¶
为什么用交叉熵做损失函数?
由于 \(H(P_{data})\) 是常数,最小化交叉熵 = 最小化KL散度 = 让模型分布接近数据分布。
def cross_entropy(p, q):
"""交叉熵H(p, q)"""
q = np.clip(q, 1e-10, 1) # 数值稳定
return -np.sum(p * np.log(q))
def kl_divergence(p, q):
"""KL散度D_KL(p||q)"""
p, q = np.array(p), np.array(q)
mask = p > 0
return np.sum(p[mask] * np.log(p[mask] / q[mask]))
p = [0.7, 0.2, 0.1] # 真实分布
q = [0.6, 0.3, 0.1] # 模型分布
print(f"H(p): {entropy(p):.4f}")
print(f"H(p, q): {cross_entropy(p, q):.4f}")
print(f"D_KL(p||q): {kl_divergence(p, q):.4f}")
print(f"验证: H(p) + D_KL = {entropy(p) + kl_divergence(p, q):.4f}") # 应等于H(p,q)
5. ML/DL中的概率统计¶
5.1 损失函数的概率解释¶
| 损失函数 | 概率解释 | 假设 |
|---|---|---|
| MSE | 高斯分布MLE | 噪声 \(\sim N(0, \sigma^2)\) |
| 交叉熵 | 多项分布MLE | 类别概率 |
| L2正则 | 高斯先验MAP | 权重 \(\sim N(0, \lambda^{-1})\) |
| L1正则 | 拉普拉斯先验MAP | 稀疏权重 |
5.2 VAE的ELBO推导¶
KL散度解析解推导:
设编码器输出 \(q(z|x) = \mathcal{N}(\mu, \sigma^2)\),先验 \(p(z) = \mathcal{N}(0, I)\),则:
对于两个高斯分布 \(q = \mathcal{N}(\mu_q, \sigma_q^2)\) 和 \(p = \mathcal{N}(\mu_p, \sigma_p^2)\),KL散度有解析公式:
代入 \(\mu_p = 0, \sigma_p = 1\):
对多元情况(独立高斯),求和:
用 \(\log\text{var} = \log \sigma^2\) 表示:
import torch
def vae_loss(x_recon, x, mu, log_var):
"""VAE损失 = 重构损失 + KL散度"""
# 重构损失 = E_q[log p(x|z)]
recon_loss = torch.nn.functional.binary_cross_entropy(
x_recon, x, reduction='sum')
# KL散度 = D_KL(q(z|x) || p(z))
# 解析解推导见上:
# D_KL = -0.5 * sum(1 + log_var - mu^2 - exp(log_var))
kl_loss = -0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp())
return recon_loss + kl_loss
🎓 面试常考题¶
- MLE和MAP的区别? — MAP多了先验,L2正则=高斯先验MAP
- KL散度为什么不对称? — \(D_{KL}(P\|Q)\)惩罚\(Q\)在\(P\)高概率处的低概率,反之不同
- 为什么分类用交叉熵不用MSE? — 交叉熵在softmax场景下梯度更稳定,MSE更容易出现梯度过小的问题
- EM算法一定收敛吗? — 是的,每步不减少似然,但可能到局部最优
- 贝叶斯公式手推后验 — 给定先验和似然,推后验分布
- 解释ELBO — 对数似然的下界,VAE优化目标
- 什么是共轭先验? — 后验和先验形式相同(如Beta-Bernoulli)
- 信息增益是什么? — 父节点熵减去加权子节点熵,决策树分裂准则
📖 6. EM算法完整推导¶
6.1 问题设定¶
观测数据 \(X\),隐变量 \(Z\),参数 \(\theta\)。目标是最大化不完全数据的对数似然:
直接优化困难(log里有sum),EM通过迭代下界来解决。
6.2 ELBO推导¶
对任意分布 \(q(Z)\):
(Jensen不等式,因为log是凹函数)
右侧就是ELBO(Evidence Lower Bound):
等号成立条件:Jensen不等式对严格凹函数(\(\log\))取等,当且仅当随机变量为常数,即 \(\frac{p(X, Z|\theta)}{q(Z)}\) 关于 \(Z\) 为常数。这要求 \(q(Z) \propto p(X, Z|\theta)\),归一化后得 \(q(Z) = p(Z|X, \theta)\)(后验分布)。
6.3 EM两步¶
- E步:\(q^{(t)}(Z) = p(Z|X, \theta^{(t)})\),计算后验(使ELBO紧贴似然)
- M步:\(\theta^{(t+1)} = \arg\max_\theta \mathbb{E}_{q^{(t)}}[\log p(X, Z|\theta)]\),最大化期望完全数据似然
6.4 GMM的EM实现¶
import numpy as np
from scipy.stats import multivariate_normal
class GaussianMixtureEM:
"""高斯混合模型的EM实现"""
def __init__(self, n_components=3, max_iter=100, tol=1e-6):
self.K = n_components
self.max_iter = max_iter
self.tol = tol
def fit(self, X):
n, d = X.shape
# 初始化
np.random.seed(42)
self.pi = np.ones(self.K) / self.K # 混合权重
indices = np.random.choice(n, self.K, replace=False)
self.mu = X[indices].copy() # 均值
self.sigma = [np.eye(d) for _ in range(self.K)] # 协方差(不能用[]*K,会共享引用)
log_likelihoods = []
for iteration in range(self.max_iter):
# === E步:计算责任度 γ(z_nk) ===
gamma = np.zeros((n, self.K))
for k in range(self.K):
gamma[:, k] = self.pi[k] * multivariate_normal.pdf(
X, mean=self.mu[k], cov=self.sigma[k]
)
gamma /= gamma.sum(axis=1, keepdims=True) # 归一化
# === M步:更新参数 ===
N_k = gamma.sum(axis=0) # 每个分量的有效样本数
for k in range(self.K):
# 更新均值
self.mu[k] = (gamma[:, k:k+1].T @ X / N_k[k]).flatten()
# 更新协方差
diff = X - self.mu[k]
self.sigma[k] = (diff.T @ (diff * gamma[:, k:k+1])) / N_k[k]
self.sigma[k] += 1e-6 * np.eye(d) # 正则化防奇异
# 更新混合权重
self.pi = N_k / n
# 计算对数似然
ll = 0
for k in range(self.K):
ll += self.pi[k] * multivariate_normal.pdf(
X, mean=self.mu[k], cov=self.sigma[k]
)
log_likelihood = np.log(ll + 1e-300).sum() # 链式调用,连续执行多个方法
log_likelihoods.append(log_likelihood)
if iteration > 0 and abs(log_likelihoods[-1] - log_likelihoods[-2]) < self.tol: # [-1]负索引取最后一个元素
print(f"EM在第{iteration}轮收敛")
break
return gamma, log_likelihoods
# 生成测试数据
np.random.seed(0)
X = np.vstack([
np.random.randn(100, 2) + [2, 2],
np.random.randn(100, 2) + [-2, -2],
np.random.randn(100, 2) + [2, -2]
])
gmm = GaussianMixtureEM(n_components=3)
gamma, lls = gmm.fit(X)
print(f"混合权重: {gmm.pi.round(3)}")
print(f"最终对数似然: {lls[-1]:.2f}")
📖 7. VAE的概率框架¶
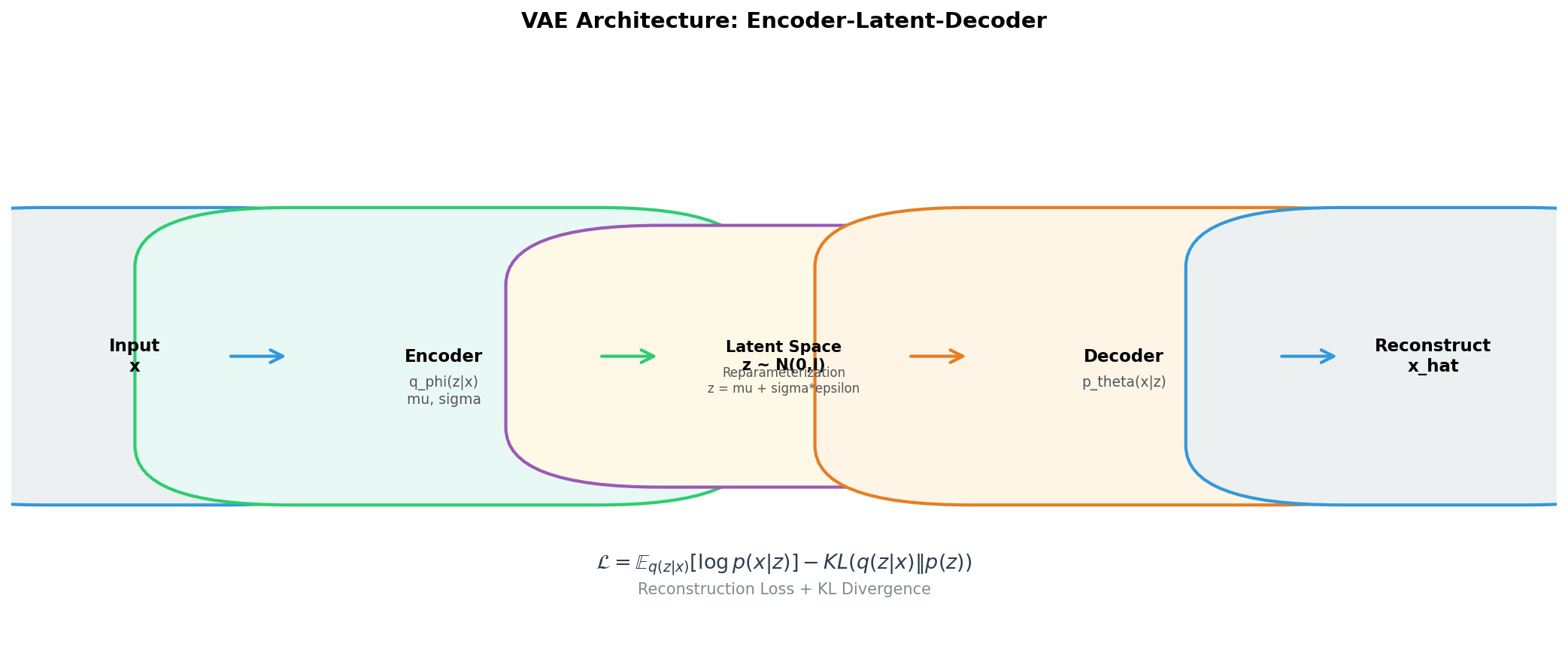
7.1 生成模型视角¶
VAE将数据生成看作:\(z \sim p(z) = \mathcal{N}(0, I)\),\(x \sim p_\theta(x|z)\)
目标:最大化 \(\log p_\theta(x)\),但 \(p_\theta(x) = \int p_\theta(x|z)p(z)dz\) 不可解。
7.2 变分推断¶
引入编码器 \(q_\phi(z|x)\) 近似后验 \(p_\theta(z|x)\),推导如下:
将 \(\frac{q_\phi(z|x)}{q_\phi(z|x)}\) 插入并拆分:
因为KL ≥ 0,所以ELBO是下界。进一步展开ELBO:
- 第一项:重构损失(解码器要从z准确重建x)
- 第二项:正则化(编码器不能偏离先验太远)
7.3 重参数化技巧¶
\(q_\phi(z|x) = \mathcal{N}(\mu_\phi(x), \sigma_\phi^2(x))\)
采样 \(z = \mu + \sigma \odot \epsilon\),\(\epsilon \sim \mathcal{N}(0, I)\)
import torch
import torch.nn as nn
class VAE(nn.Module): # 继承nn.Module定义神经网络层
def __init__(self, input_dim=784, latent_dim=20):
super().__init__() # super()调用父类方法
# 编码器 q(z|x)
self.encoder = nn.Sequential(
nn.Linear(input_dim, 256), nn.ReLU(),
nn.Linear(256, 128), nn.ReLU()
)
self.fc_mu = nn.Linear(128, latent_dim)
self.fc_logvar = nn.Linear(128, latent_dim)
# 解码器 p(x|z)
self.decoder = nn.Sequential(
nn.Linear(latent_dim, 128), nn.ReLU(),
nn.Linear(128, 256), nn.ReLU(),
nn.Linear(256, input_dim), nn.Sigmoid()
)
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def forward(self, x):
h = self.encoder(x)
mu, logvar = self.fc_mu(h), self.fc_logvar(h)
z = self.reparameterize(mu, logvar)
return self.decoder(z), mu, logvar
def vae_loss(recon_x, x, mu, logvar):
"""ELBO = 重构损失 + KL散度"""
recon = nn.functional.binary_cross_entropy(recon_x, x, reduction='sum')
# KL(N(mu, sigma) || N(0, I)) 的解析解
kl = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return recon + kl
vae = VAE()
x = torch.randn(32, 784).sigmoid() # 模拟输入
recon, mu, logvar = vae(x)
loss = vae_loss(recon, x, mu, logvar)
print(f"ELBO loss: {loss.item():.2f}") # .item()将单元素张量转为Python数值
📖 8. MCMC采样方法¶
8.1 Metropolis-Hastings算法¶
当后验分布 \(p(\theta|D)\) 没有解析形式时,用MCMC采样。
import numpy as np
def metropolis_hastings(log_target, initial, n_samples=10000, proposal_std=1.0):
"""
Metropolis-Hastings MCMC采样
Args:
log_target: 目标分布的对数密度(不需要归一化常数)
initial: 初始点
n_samples: 采样数量
proposal_std: 提议分布标准差
"""
samples = [initial]
current = initial
accepted = 0
for _ in range(n_samples):
# 提议新样本(对称随机游走)
proposal = current + np.random.randn(*current.shape) * proposal_std
# 计算接受概率(对数空间避免溢出)
log_alpha = log_target(proposal) - log_target(current)
# 接受/拒绝
if np.log(np.random.rand()) < log_alpha:
current = proposal
accepted += 1
samples.append(current.copy())
acceptance_rate = accepted / n_samples
return np.array(samples), acceptance_rate
# 示例:采样二维高斯后验
def log_posterior(theta):
"""模拟一个多模态后验分布"""
mu1, mu2 = np.array([2, 2]), np.array([-2, -2])
return np.logaddexp(
-0.5 * np.sum((theta - mu1)**2),
-0.5 * np.sum((theta - mu2)**2)
)
samples, acc_rate = metropolis_hastings(
log_posterior, np.array([0.0, 0.0]), n_samples=50000, proposal_std=1.5
)
print(f"接受率: {acc_rate:.2%} (经验范围: 20-50%)")
print(f"后验均值: {samples[5000:].mean(axis=0).round(3)}") # burn-in 5000
print(f"后验标准差: {samples[5000:].std(axis=0).round(3)}")
8.2 贝叶斯深度学习简述¶
将神经网络权重视为随机变量 \(w \sim p(w|D)\),预测时积分:
实用近似方法: - MC Dropout:训练时Dropout,推理时也保持Dropout → 多次前传取均值和方差 - 深度集成:训练多个独立模型,预测取平均 - Laplace近似:在MAP解处做二阶Taylor展开
🎯 面试高频题(扩展)¶
- EM和梯度下降的区别? — EM是坐标上升(交替优化q和θ),不需要学习率,但每步可能计算量大;梯度下降是一阶近似,更通用
- VAE和AE的本质区别? — AE只学确定性映射,VAE学分布(编码器输出μ和σ),有正则化(KL项)使隐空间连续可插值
- 重参数化技巧为什么需要? — 直接采样z~q(z|x)不可微,无法反向传播;重参数化将随机性移到外部ε,使梯度可以流过μ和σ
- MCMC收敛怎么判断? — 链的自相关性下降,多链的Gelman-Rubin统计量R̂≈1,trace plot无趋势
- 贝叶斯方法的优缺点? — 优:自然的不确定性量化、防过拟合(自动奥卡姆剃刀)。缺:计算昂贵、先验选择主观
- 为什么推荐系统喜欢用概率模型? — 可以处理缺失值(缺失即隐变量)、量化不确定性、自然处理冷启动(通过先验)
✅ 学习检查清单¶
- 能手算贝叶斯公式(如疾病检测问题)
- 能推导高斯分布的MLE
- 能解释MLE、MAP、贝叶斯估计的联系
- 能手写EM算法实现GMM
- 能计算熵、KL散度、交叉熵并解释关系
- 能解释为什么分类任务用交叉熵损失