📐 线性代数基础¶
难度:⭐⭐⭐ | 预计学习时间:8-10小时 | 重要性:AI面试必考
🎯 学习目标¶
- 理解向量空间、基、维度的核心概念
- 掌握矩阵运算、特征分解、SVD的数学原理
- 能手写PCA推导并用NumPy实现
- 理解注意力机制中的矩阵运算
1. 向量与向量空间¶

1.1 向量基本运算¶
import numpy as np
# 向量定义
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
# 内积(点积): 衡量相似度
dot = np.dot(a, b) # 1*4 + 2*5 + 3*6 = 32
print(f"内积: {dot}")
# 外积: 生成矩阵
outer = np.outer(a, b) # 3x3矩阵
print(f"外积:\n{outer}")
# 范数
l2_norm = np.linalg.norm(a) # L2范数 = sqrt(14)
l1_norm = np.linalg.norm(a, 1) # L1范数 = 6
linf_norm = np.linalg.norm(a, np.inf) # L∞范数 = 3
print(f"L2范数: {l2_norm:.4f}, L1范数: {l1_norm}, L∞范数: {linf_norm}")
# 余弦相似度: AI中最常用的相似度度量
cos_sim = np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
print(f"余弦相似度: {cos_sim:.4f}")
1.2 线性无关与基¶
AI中的意义:嵌入空间的维度 = 基向量的数量。Word2Vec的300维空间意味着用300个线性无关的方向来表示语义。
1.3 线性变换¶
# 线性变换可视化
import matplotlib.pyplot as plt
# 原始单位圆上的点
theta = np.linspace(0, 2*np.pi, 100)
circle = np.array([np.cos(theta), np.sin(theta)])
# 变换矩阵(拉伸+旋转)
A = np.array([[2, 1], [0, 1.5]])
transformed = A @ circle
fig, axes = plt.subplots(1, 2, figsize=(10, 4))
axes[0].plot(circle[0], circle[1]); axes[0].set_title("原始")
axes[1].plot(transformed[0], transformed[1]); axes[1].set_title("变换后")
plt.show()
2. 矩阵运算与性质¶
2.1 核心矩阵运算¶
A = np.array([[1, 2], [3, 4]])
# 转置
print(f"转置:\n{A.T}")
# 行列式: det(A) = ad - bc
det = np.linalg.det(A) # 1*4 - 2*3 = -2
print(f"行列式: {det:.4f}")
# 逆矩阵: AA^{-1} = I
A_inv = np.linalg.inv(A)
print(f"逆矩阵:\n{A_inv}")
print(f"验证 A @ A^-1 = I:\n{A @ A_inv}")
# 秩
rank = np.linalg.matrix_rank(A)
print(f"秩: {rank}")
# 迹: tr(A) = 对角元素之和 = 特征值之和
trace = np.trace(A) # 1+4 = 5
print(f"迹: {trace}")
2.2 正定矩阵¶
等价条件:所有特征值 > 0 | 所有顺序主子式 > 0 | Cholesky分解 \(A = LL^T\) 存在
正定 \(\iff\) 所有特征值 > 0 的证明:
(\(\Rightarrow\))设 \(A\) 正定,\(\lambda\) 为任一特征值,\(v\) 为对应特征向量(\(v \neq 0\))。则 \(v^TAv = v^T(\lambda v) = \lambda \|v\|^2\)。由正定性 \(v^TAv > 0\) 且 \(\|v\|^2 > 0\),故 \(\lambda > 0\)。
(\(\Leftarrow\))设所有特征值 \(\lambda_i > 0\)。对称矩阵可正交对角化 \(A = Q\Lambda Q^T\)。对任意 \(x \neq 0\),令 \(y = Q^Tx\)(\(y \neq 0\),因 \(Q\) 正交),则 \(x^TAx = y^T\Lambda y = \sum_i \lambda_i y_i^2 > 0\)。
AI中的意义:协方差矩阵是半正定的;Hessian矩阵正定意味着凸函数(有唯一最小值)。
3. 特征值与特征分解¶
3.1 定义与求解¶
A = np.array([[4, 2], [1, 3]])
# 特征分解
eigenvalues, eigenvectors = np.linalg.eig(A)
print(f"特征值: {eigenvalues}") # [5, 2]
print(f"特征向量:\n{eigenvectors}")
# 验证: Av = λv
for i in range(len(eigenvalues)):
v = eigenvectors[:, i]
lam = eigenvalues[i]
print(f"Av = {A @ v}, λv = {lam * v}") # 应该相等
3.2 特征分解¶
对称矩阵 \(A = Q\Lambda Q^T\),其中: - \(Q\) = 特征向量矩阵(正交) - \(\Lambda\) = 对角特征值矩阵
# 对称矩阵特征分解
S = np.array([[3, 1], [1, 3]])
eigenvalues, Q = np.linalg.eigh(S) # eigh专用于对称矩阵
Lambda = np.diag(eigenvalues)
# 验证 S = QΛQ^T
S_reconstructed = Q @ Lambda @ Q.T
print(f"重构误差: {np.max(np.abs(S - S_reconstructed)):.2e}")
3.3 几何意义¶
特征向量 = 变换不改变方向的向量,特征值 = 沿该方向的缩放因子。
AI中的意义: - PCA的主成分 = 协方差矩阵的特征向量(数据方差最大的方向) - PageRank = 转移矩阵的主特征向量 - 频谱聚类 = 拉普拉斯矩阵的特征分解
4. 奇异值分解(SVD)¶

4.1 定义¶
任意矩阵 \(A_{m \times n}\) 可分解为:
- \(U_{m \times m}\):左奇异向量矩阵(正交)
- \(\Sigma_{m \times n}\):奇异值对角矩阵(\(\sigma_1 \geq \sigma_2 \geq ... \geq 0\))
- \(V_{n \times n}\):右奇异向量矩阵(正交)
4.2 与特征分解的关系¶
由SVD定义 \(A = U\Sigma V^T\),计算 \(A^TA\):
其中用到了 \(U^TU = I\)(正交性)。这恰好是 \(A^TA\) 的特征分解形式,因为 \(\Sigma^T\Sigma\) 是对角矩阵,对角元素为 \(\sigma_i^2\)。
同理,\(AA^T = U\Sigma V^TV\Sigma^TU^T = U\Sigma\Sigma^T U^T\)(用到 \(V^TV = I\)):
4.3 低秩近似(图像压缩)¶
# 用SVD压缩图像
def svd_compress(image_matrix, k):
"""保留前k个奇异值"""
U, s, Vt = np.linalg.svd(image_matrix, full_matrices=False)
# 截断
U_k = U[:, :k]
s_k = np.diag(s[:k])
Vt_k = Vt[:k, :]
return U_k @ s_k @ Vt_k
# 原始: m*n个存储, 压缩后: k*(m+n+1)个存储
m, n = 512, 512
for k in [5, 20, 50, 100]:
ratio = k * (m + n + 1) / (m * n)
print(f"k={k}: 压缩率 {ratio:.2%}")
Eckart-Young定理:SVD的前k项截断是最优的秩k近似(在Frobenius范数意义下)。
5. 主成分分析(PCA)¶
5.1 数学推导¶
目标:找到方向 \(\mathbf{w}\) 使投影后的方差最大
用拉格朗日乘子法:
结论:最优方向 = 协方差矩阵的特征向量,方差 = 对应特征值。因此,第一主成分对应最大特征值的特征向量(方差最大方向),第二主成分对应第二大特征值,以此类推。
5.2 NumPy手写PCA¶
def pca_from_scratch(X, n_components):
"""手写PCA实现"""
# 1. 中心化
X_centered = X - X.mean(axis=0)
# 2. 计算协方差矩阵
cov_matrix = np.cov(X_centered.T)
# 3. 特征分解
eigenvalues, eigenvectors = np.linalg.eigh(cov_matrix)
# 4. 按特征值降序排列
idx = np.argsort(eigenvalues)[::-1]
eigenvalues = eigenvalues[idx]
eigenvectors = eigenvectors[:, idx]
# 5. 选取前n_components个主成分
W = eigenvectors[:, :n_components]
# 6. 投影
X_projected = X_centered @ W
# 方差解释比例
explained_var_ratio = eigenvalues[:n_components] / eigenvalues.sum()
return X_projected, explained_var_ratio
# 测试
np.random.seed(42)
X = np.random.randn(100, 5) # 100个样本,5个特征
X_pca, ratios = pca_from_scratch(X, 2)
print(f"前2个主成分解释方差比例: {ratios}")
print(f"投影后形状: {X_pca.shape}") # (100, 2)
6. AI中的线性代数应用¶
6.1 注意力机制中的矩阵运算¶
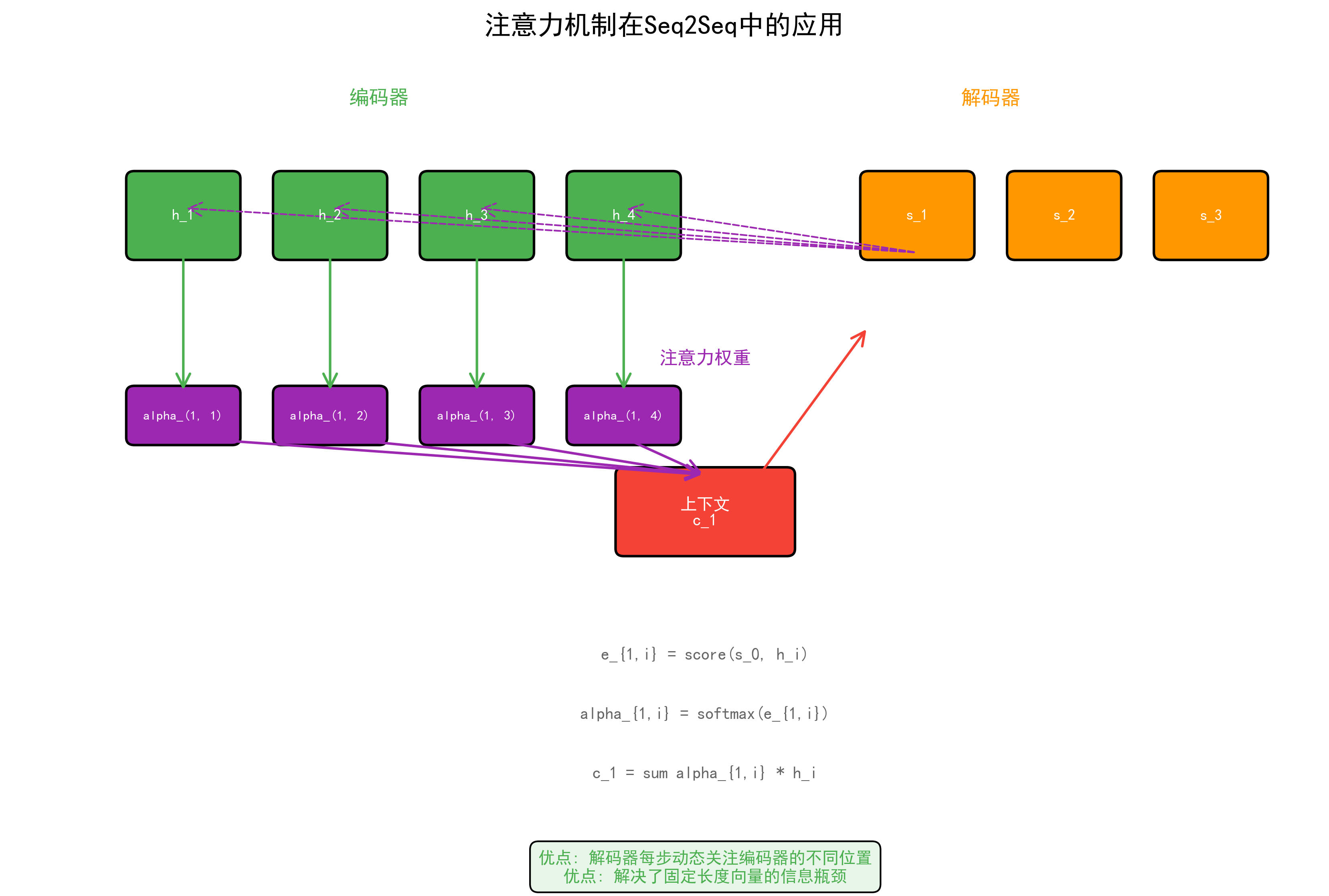
import torch
import torch.nn.functional as F
def scaled_dot_product_attention(Q, K, V, mask=None):
"""
Q: [batch, heads, seq_len, d_k]
K: [batch, heads, seq_len, d_k]
V: [batch, heads, seq_len, d_v]
"""
d_k = Q.size(-1)
# QK^T: [batch, heads, seq_len, seq_len]
scores = torch.matmul(Q, K.transpose(-2, -1)) / (d_k ** 0.5)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# softmax归一化
attention_weights = F.softmax(scores, dim=-1)
# 加权求和: [batch, heads, seq_len, d_v]
output = torch.matmul(attention_weights, V)
return output, attention_weights
# 示例
batch, heads, seq_len, d_k = 2, 8, 10, 64
Q = torch.randn(batch, heads, seq_len, d_k)
K = torch.randn(batch, heads, seq_len, d_k)
V = torch.randn(batch, heads, seq_len, d_k)
output, weights = scaled_dot_product_attention(Q, K, V)
print(f"输出形状: {output.shape}") # [2, 8, 10, 64]
print(f"注意力权重形状: {weights.shape}") # [2, 8, 10, 10]
6.2 嵌入空间的线性结构¶
# Word2Vec经典类比: king - man + woman ≈ queen
# 这依赖于嵌入空间中的线性关系
embeddings = {
"king": np.array([0.5, 0.8, 0.1]),
"queen": np.array([0.5, 0.1, 0.8]),
"man": np.array([0.2, 0.7, 0.1]),
"woman": np.array([0.2, 0.1, 0.7]),
}
result = embeddings["king"] - embeddings["man"] + embeddings["woman"]
print(f"king - man + woman = {result}")
print(f"queen = {embeddings['queen']}")
# 两者应该非常接近
🎓 面试常考题¶
- SVD和PCA的关系是什么? — PCA = 对中心化数据矩阵做SVD
- 特征值的物理意义? — 沿特征向量方向的缩放因子
- 为什么注意力机制要除以\(\sqrt{d_k}\)? — 防止点积值过大导致softmax饱和
- 矩阵求导:\(\frac{\partial \mathbf{x}^T A \mathbf{x}}{\partial \mathbf{x}} = ?\) — \((A + A^T)\mathbf{x}\)
- 正交矩阵有什么好的性质? — 保持向量长度和角度,\(Q^{-1} = Q^T\)
- 低秩矩阵在AI中的应用? — LoRA微调(低秩适应)、矩阵补全(推荐系统)
- 对称矩阵的特征值一定是实数吗? — 是,且特征向量正交
- 如何判断一个矩阵是否正定? — 所有特征值 > 0 / Cholesky分解存在
📖 7. SVD在推荐系统中的应用¶
7.1 评分矩阵分解¶
推荐系统的核心是将用户-物品评分矩阵 \(R_{m \times n}\) 分解为低秩近似:
其中 \(k \ll \min(m, n)\) 是隐因子维度,\(U\) 的每一行代表用户的隐向量,\(V\) 的每一行代表物品的隐向量。
7.2 截断SVD推荐实现¶
import numpy as np
from scipy.sparse.linalg import svds
def svd_recommend(ratings_matrix, k=20, top_n=10):
"""
基于截断SVD的推荐系统
Args:
ratings_matrix: 用户-物品评分矩阵 (m x n),0表示未评分
k: 隐因子维度
top_n: 推荐数量
"""
# 用户均值归一化(处理评分偏置,只对已评分项取均值)
mask = ratings_matrix != 0
user_ratings_mean = np.where(
mask.sum(axis=1, keepdims=True) > 0,
(ratings_matrix * mask).sum(axis=1, keepdims=True) / mask.sum(axis=1, keepdims=True),
0
)
R_normalized = (ratings_matrix - user_ratings_mean) * mask # 未评分项保持为0
# 截断SVD分解
U, sigma, Vt = svds(R_normalized, k=k)
sigma = np.diag(sigma)
# 预测评分矩阵
predicted_ratings = U @ sigma @ Vt + user_ratings_mean
# 为每个用户生成推荐
recommendations = {}
for user_idx in range(ratings_matrix.shape[0]):
# 找到用户未评分的物品
unrated = np.where(ratings_matrix[user_idx, :] == 0)[0]
# 按预测评分排序
pred_scores = predicted_ratings[user_idx, unrated]
top_items = unrated[np.argsort(pred_scores)[::-1][:top_n]]
recommendations[user_idx] = top_items
return predicted_ratings, recommendations
# 示例
np.random.seed(42)
R = np.random.randint(0, 6, (50, 30)).astype(float) # 50用户30物品
R[R < 2] = 0 # 模拟稀疏矩阵
pred, recs = svd_recommend(R, k=5, top_n=5)
print(f"用户0的Top-5推荐物品: {recs[0]}")
print(f"预测评分: {pred[0, recs[0]].round(2)}")
7.3 SVD与LoRA的连接¶
LoRA利用低秩近似思想,可用SVD直觉来理解:
其中 \(B \in \mathbb{R}^{d \times r}, A \in \mathbb{R}^{r \times k}\),\(r \ll \min(d, k)\)。
import torch
import torch.nn as nn
class LoRALinear(nn.Module): # 继承nn.Module定义神经网络层
"""LoRA线性层 - SVD低秩思想的直接应用"""
def __init__(self, in_features, out_features, rank=4, alpha=1.0): # __init__构造方法,创建对象时自动调用
super().__init__() # super()调用父类方法
self.linear = nn.Linear(in_features, out_features, bias=False)
self.linear.weight.requires_grad = False # 冻结原始权重
# 低秩分解 ΔW = B @ A
self.lora_A = nn.Parameter(torch.randn(rank, in_features) * 0.01)
self.lora_B = nn.Parameter(torch.zeros(out_features, rank))
self.scale = alpha / rank
def forward(self, x):
# W @ x + scale * (B @ A) @ x
return self.linear(x) + self.scale * (x @ self.lora_A.T @ self.lora_B.T)
# LoRA参数量对比
d, k, r = 4096, 4096, 8
print(f"全量参数: {d * k:,} = {d*k/1e6:.1f}M")
print(f"LoRA参数: {d * r + r * k:,} = {(d*r + r*k)/1e6:.3f}M")
print(f"压缩比: {d * k / (d * r + r * k):.0f}x")
📖 8. 注意力机制的完整矩阵推导¶
8.1 Scaled Dot-Product Attention 推导¶
给定查询 \(Q \in \mathbb{R}^{n \times d_k}\),键 \(K \in \mathbb{R}^{m \times d_k}\),值 \(V \in \mathbb{R}^{m \times d_v}\):
Step 1: 计算注意力分数
其中 \(S_{ij} = q_i^T k_j = \sum_{l=1}^{d_k} q_{il} k_{jl}\)
Step 2: 为什么要除以 \(\sqrt{d_k}\)?
假设 \(q_i, k_j\) 的各分量独立同分布,均值为0,方差为1:
由于 \(E[q_{il}] = E[k_{jl}] = 0\) 且彼此独立,每个乘积项的方差为:
各项独立,因此方差可加:
当 \(d_k\) 很大时,\(S_{ij}\) 方差很大 → softmax梯度极小(进入饱和区)。
除以 \(\sqrt{d_k}\) 后方差归一化为1:
8.2 Multi-Head Attention 完整推导¶
其中每个头:
参数矩阵:\(W_i^Q \in \mathbb{R}^{d_{model} \times d_k}\),\(W_i^K \in \mathbb{R}^{d_{model} \times d_k}\),\(W_i^V \in \mathbb{R}^{d_{model} \times d_v}\),\(W^O \in \mathbb{R}^{hd_v \times d_{model}}\)
通常取 \(d_k = d_v = d_{model} / h\),所以Multi-Head的总计算量与单头 \(d_{model}\) 维attention相同。
8.3 反向传播中的梯度流¶
Softmax + Attention的梯度:
设 \(A = \text{softmax}(S / \sqrt{d_k})\),输出 \(O = AV\)
Softmax的Jacobian:
这保证了梯度能稳定回传,是Transformer训练成功的关键。
import torch
import torch.nn.functional as F
def attention_with_gradient_check(Q, K, V):
"""验证注意力机制的梯度"""
Q.requires_grad_(True)
K.requires_grad_(True)
V.requires_grad_(True)
d_k = Q.size(-1)
scores = torch.matmul(Q, K.transpose(-2, -1)) / (d_k ** 0.5)
attn_weights = F.softmax(scores, dim=-1)
output = torch.matmul(attn_weights, V)
# 反向传播
loss = output.sum()
loss.backward() # 反向传播计算梯度
print(f"Q梯度范围: [{Q.grad.min():.4f}, {Q.grad.max():.4f}]")
print(f"K梯度范围: [{K.grad.min():.4f}, {K.grad.max():.4f}]")
print(f"V梯度范围: [{V.grad.min():.4f}, {V.grad.max():.4f}]")
print(f"注意力权重熵: {-(attn_weights * attn_weights.log()).sum(-1).mean():.4f}")
return output, attn_weights
# 测试
Q = torch.randn(2, 4, 64) # (batch, seq_len, d_k)
K = torch.randn(2, 6, 64)
V = torch.randn(2, 6, 64)
out, weights = attention_with_gradient_check(Q, K, V)
print(f"输出形状: {out.shape}, 权重形状: {weights.shape}")
📖 9. 数值线性代数与稳定性¶
9.1 浮点数陷阱¶
import numpy as np
# 陷阱1: 大数吃小数
a = 1e16
b = 1.0
print(f"(a + b) - a = {(a + b) - a}") # 期望1.0,实际0.0
# 陷阱2: 矩阵条件数
A = np.array([[1, 1], [1, 1.0001]])
print(f"条件数: {np.linalg.cond(A):.0f}") # 极大 → 求逆不稳定
b = np.array([2, 2.0001])
x = np.linalg.solve(A, b)
print(f"解: {x}") # 解对b的微小扰动极其敏感
# 安全的log-sum-exp
def stable_logsumexp(x):
"""数值稳定的log(sum(exp(x)))"""
c = np.max(x)
return c + np.log(np.sum(np.exp(x - c)))
x = np.array([1000, 1001, 1002])
print(f"不稳定: {np.log(np.sum(np.exp(x)))}") # inf
print(f"稳定版: {stable_logsumexp(x):.4f}") # 正确结果
9.2 Cholesky分解(高斯过程核心)¶
正定矩阵 \(A = LL^T\),用于高效求解线性系统和采样:
def cholesky_solve(A, b):
"""用Cholesky分解求解Ax=b(A正定时通常更高效)"""
L = np.linalg.cholesky(A)
# Ly = b (前代)
y = np.linalg.solve(L, b)
# L^T x = y (回代)
x = np.linalg.solve(L.T, y)
return x
# 高斯过程中的应用:从多维高斯采样
def sample_multivariate_gaussian(mu, cov, n_samples=5):
"""利用Cholesky从N(mu, cov)中采样"""
L = np.linalg.cholesky(cov + 1e-6 * np.eye(len(mu))) # 加jitter保正定
z = np.random.randn(len(mu), n_samples)
return mu[:, None] + L @ z
mu = np.zeros(3)
cov = np.array([[1, 0.8, 0.3], [0.8, 1, 0.5], [0.3, 0.5, 1]])
samples = sample_multivariate_gaussian(mu, cov, 1000)
print(f"采样均值: {samples.mean(axis=1).round(3)}")
print(f"采样协方差:\n{np.cov(samples).round(3)}")
🎯 面试高频题(扩展)¶
- LoRA为什么有效? — 常见解释是增量 \(\Delta W\) 在任务适配中呈现低秩结构,用 \(BA\) 近似可在较少参数下保持表达力
- 矩阵条件数是什么? — \(\kappa(A) = \|A\| \cdot \|A^{-1}\|\),衡量线性系统对输入扰动的敏感度。条件数大→系统病态
- Cholesky分解的前提和用途? — 前提是正定对称矩阵,\(A = LL^T\)。用于高斯过程推断、多元高斯采样、加速线性系统求解
- SVD截断近似为什么是最优的? — Eckart-Young定理:在Frobenius范数意义下,前k个奇异值的截断是最优秩k近似
- 嵌入空间的线性类比为什么有效? — Word2Vec等模型的训练目标隐含了共现矩阵的低秩分解,使语义关系映射为向量空间中的线性结构
- RoPE旋转位置编码的数学基础? — 利用正交矩阵(旋转矩阵)对Q/K施加位置相关变换,保持内积中编码相对位置信息
✅ 学习检查清单¶
- 能计算向量内积、外积、余弦相似度
- 能手算2x2矩阵的特征值和特征向量
- 能推导PCA的优化目标并解释为何取特征向量
- 能手写SVD图像压缩代码
- 能实现scaled dot-product attention
- 能解释注意力矩阵\(QK^T\)的含义