02-Transformer架构¶
学习时间: 约8-10小时 难度级别: ⭐⭐⭐⭐⭐ 高级 前置知识: 注意力机制详解、线性代数、PyTorch 学习目标: 完全理解Transformer架构的每个组件,能从零实现完整的Transformer
📌 定位说明:本章从深度学习基础视角讲解Transformer架构(编码器/解码器/位置编码的完整推导与实现)。面向大模型的Transformer深入理解(RoPE/RMSNorm/GeLU/编解码器架构对比等)请参考 LLM学习/01-基础巩固/01-Transformer深入理解。
目录¶
- 1. Transformer概述
- 2. 位置编码
- 3. 编码器(Encoder)
- 4. 解码器(Decoder)
- 5. Mask机制
- 6. 残差连接与LayerNorm
- 7. 从零实现完整Transformer
- 8. 训练细节
- 9. 练习与自我检查
1. Transformer概述¶
1.1 "Attention is All You Need"¶
Vaswani et al.(2017)提出 Transformer,完全抛弃了循环结构和卷积结构,仅使用注意力机制。
1.2 整体架构¶
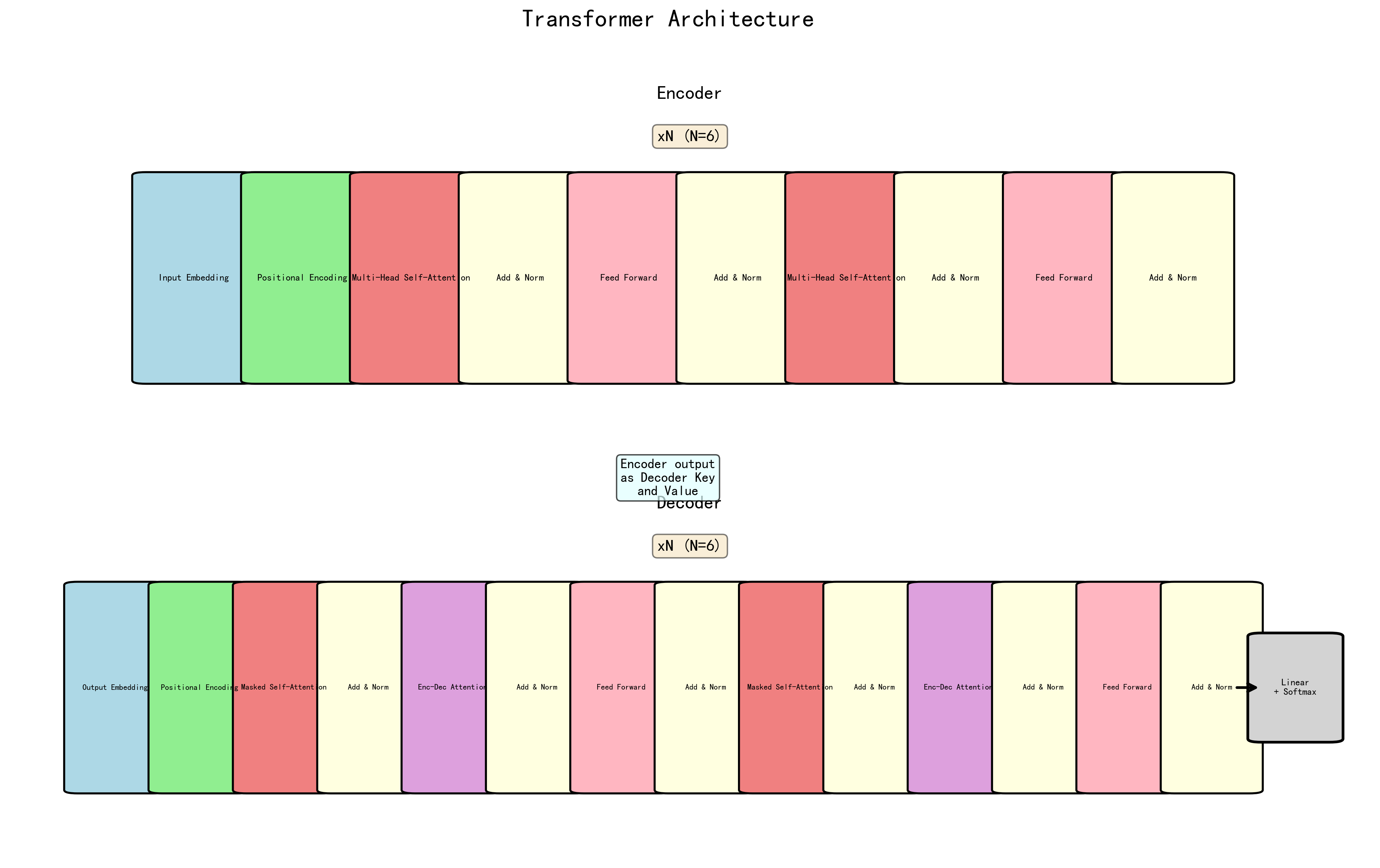
输入 → [Embedding + 位置编码] → [Encoder × N] → 编码器输出
↓
输出(shifted) → [Embedding + 位置编码] → [Decoder × N] → Linear → Softmax → 预测
- Encoder: \(N\) 层堆叠,每层 = 自注意力 + 前馈网络
- Decoder: \(N\) 层堆叠,每层 = 因果自注意力 + 交叉注意力 + 前馈网络
- 默认配置: \(N=6\), \(d_{model}=512\), \(h=8\), \(d_{ff}=2048\)
2. 位置编码¶
2.1 为什么需要位置编码¶

自注意力是置换不变的(Permutation Invariant)— 打乱输入顺序不影响输出(仅改变输出的顺序)。因此必须显式注入位置信息。
2.2 正弦位置编码¶
为什么用正弦/余弦? - 有界:值在 \([-1, 1]\) 之间 - 相对位置可通过线性变换表示:\(PE_{pos+k}\) 可以表示为 \(PE_{pos}\) 的线性函数 - 可以外推到训练中未见过的长度
import torch
import torch.nn as nn
import math
class SinusoidalPositionalEncoding(nn.Module): # 继承nn.Module定义神经网络层
"""正弦位置编码"""
def __init__(self, d_model, max_len=5000, dropout=0.1): # __init__构造方法,创建对象时自动调用
super().__init__() # super()调用父类方法
self.dropout = nn.Dropout(dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # 链式调用,连续执行多个方法 # unsqueeze增加一个维度
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0) # (1, max_len, d_model)
self.register_buffer('pe', pe)
def forward(self, x):
"""x: (batch, seq_len, d_model)"""
x = x + self.pe[:, :x.size(1)]
return self.dropout(x)
2.3 可学习位置编码¶
class LearnedPositionalEncoding(nn.Module):
"""可学习位置编码(BERT、GPT使用)"""
def __init__(self, d_model, max_len=512, dropout=0.1):
super().__init__()
self.pos_embedding = nn.Embedding(max_len, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
positions = torch.arange(x.size(1), device=x.device).unsqueeze(0)
x = x + self.pos_embedding(positions)
return self.dropout(x)
2.4 旋转位置编码(RoPE)¶

Su et al.(2021)提出的 RoPE,广泛用于 LLaMA、GPT-NeoX 等现代 LLM:
其中 \(R_{\Theta,m}^d\) 是旋转矩阵。核心思想:通过旋转将绝对位置编码转化为相对位置编码。
class RotaryPositionalEncoding(nn.Module):
"""RoPE 旋转位置编码"""
def __init__(self, d_model, max_len=2048):
super().__init__()
inv_freq = 1.0 / (10000 ** (torch.arange(0, d_model, 2).float() / d_model))
self.register_buffer('inv_freq', inv_freq)
self._build_cache(max_len)
def _build_cache(self, max_len):
t = torch.arange(max_len, device=self.inv_freq.device)
freqs = torch.outer(t, self.inv_freq)
emb = torch.cat((freqs, freqs), dim=-1)
self.register_buffer('cos_cached', emb.cos().unsqueeze(0).unsqueeze(0))
self.register_buffer('sin_cached', emb.sin().unsqueeze(0).unsqueeze(0))
@staticmethod # @staticmethod静态方法,无需实例即可调用
def rotate_half(x):
x1, x2 = x.chunk(2, dim=-1)
return torch.cat((-x2, x1), dim=-1)
def forward(self, q, k):
seq_len = q.size(2)
cos = self.cos_cached[:, :, :seq_len, :]
sin = self.sin_cached[:, :, :seq_len, :]
q_rot = q * cos + self.rotate_half(q) * sin
k_rot = k * cos + self.rotate_half(k) * sin
return q_rot, k_rot
2.5 RMSNorm(Root Mean Square Layer Normalization)¶
Zhang & Sennrich(2019)提出的 RMSNorm,是 LayerNorm 的简化版本,在现代 LLM 中广泛使用:
与 LayerNorm 的区别: - LayerNorm:计算均值和方差,减去均值,除以标准差 - RMSNorm:只计算均方根(RMS),不计算均值,更简洁
优势: - 计算效率更高(无需计算均值) - 训练稳定性好(广泛用于 LLaMA、Qwen、DeepSeek 等模型) - 可与 Pre-Norm 架构良好配合
class RMSNorm(nn.Module):
"""RMSNorm 归一化"""
def __init__(self, d_model, eps=1e-8):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(d_model))
def forward(self, x):
# x: (batch, seq_len, d_model)
rms = torch.sqrt(torch.mean(x * x, dim=-1, keepdim=True) + self.eps)
return self.weight * (x / rms)
2.6 ALiBi(Attention with Linear Biases)¶
Press et al.(2022)提出,不在 embedding 中加位置信息,而是在注意力分数中加线性偏移:
def get_alibi_slopes(num_heads):
"""计算 ALiBi 斜率"""
closest_power = 2 ** math.floor(math.log2(num_heads))
base = 2 ** (-(2 ** -(math.log2(closest_power) - 3)))
powers = torch.arange(1, closest_power + 1)
slopes = base ** powers
if closest_power != num_heads:
extra_base = 2 ** (-(2 ** -(math.log2(2 * closest_power) - 3)))
extra_powers = torch.arange(1, 2 * (num_heads - closest_power) + 1, 2)
slopes = torch.cat([slopes, extra_base ** extra_powers])
return slopes
def alibi_bias(seq_len, num_heads):
"""生成 ALiBi 偏置矩阵"""
slopes = get_alibi_slopes(num_heads)
positions = torch.arange(seq_len)
# unsqueeze(0)和unsqueeze(1)将1D位置向量广播为(seq,seq)距离矩阵
relative_positions = positions.unsqueeze(0) - positions.unsqueeze(1) # (seq, seq)
# slopes(H,)经两次unsqueeze变为(H,1,1),距离矩阵unsqueeze(0)变为(1,S,S),广播相乘得(H,S,S)
bias = -slopes.unsqueeze(1).unsqueeze(1) * relative_positions.abs().unsqueeze(0)
return bias # (num_heads, seq, seq)
3. 编码器(Encoder)¶
class FeedForward(nn.Module):
"""前馈网络(Position-wise Feed-Forward)"""
def __init__(self, d_model, d_ff, dropout=0.1):
super().__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.linear2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
self.activation = nn.GELU() # 原始论文用 ReLU,现代通常用 GELU
def forward(self, x):
return self.linear2(self.dropout(self.activation(self.linear1(x))))
class EncoderLayer(nn.Module):
"""Transformer 编码器层"""
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super().__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.ffn = FeedForward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
def forward(self, x, src_mask=None):
# Post-Norm: Norm(x + Sublayer(x))
attn_out, attn_weights = self.self_attn(x, x, x, src_mask)
x = self.norm1(x + self.dropout1(attn_out))
ffn_out = self.ffn(x)
x = self.norm2(x + self.dropout2(ffn_out))
return x, attn_weights
class TransformerEncoder(nn.Module):
"""Transformer 编码器"""
def __init__(self, vocab_size, d_model, num_heads, d_ff, num_layers,
max_len=5000, dropout=0.1):
super().__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.pos_encoding = SinusoidalPositionalEncoding(d_model, max_len, dropout)
self.layers = nn.ModuleList([
EncoderLayer(d_model, num_heads, d_ff, dropout)
for _ in range(num_layers)
])
self.norm = nn.LayerNorm(d_model)
self.scale = math.sqrt(d_model)
def forward(self, src, src_mask=None):
x = self.embedding(src) * self.scale
x = self.pos_encoding(x)
for layer in self.layers:
x, _ = layer(x, src_mask)
return self.norm(x)
4. 解码器(Decoder)¶
class DecoderLayer(nn.Module):
"""Transformer 解码器层"""
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super().__init__()
# 1. 因果自注意力(Masked Self-Attention)
self.self_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.norm1 = nn.LayerNorm(d_model)
# 2. 交叉注意力(Cross-Attention)
self.cross_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.norm2 = nn.LayerNorm(d_model)
# 3. 前馈网络
self.ffn = FeedForward(d_model, d_ff, dropout)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, enc_output, src_mask=None, tgt_mask=None):
# 因果自注意力
self_attn_out, _ = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout(self_attn_out))
# 交叉注意力
cross_attn_out, cross_weights = self.cross_attn(x, enc_output, enc_output, src_mask)
x = self.norm2(x + self.dropout(cross_attn_out))
# 前馈网络
ffn_out = self.ffn(x)
x = self.norm3(x + self.dropout(ffn_out))
return x, cross_weights
class TransformerDecoder(nn.Module):
"""Transformer 解码器"""
def __init__(self, vocab_size, d_model, num_heads, d_ff, num_layers,
max_len=5000, dropout=0.1):
super().__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.pos_encoding = SinusoidalPositionalEncoding(d_model, max_len, dropout)
self.layers = nn.ModuleList([
DecoderLayer(d_model, num_heads, d_ff, dropout)
for _ in range(num_layers)
])
self.norm = nn.LayerNorm(d_model)
self.scale = math.sqrt(d_model)
def forward(self, tgt, enc_output, src_mask=None, tgt_mask=None):
x = self.embedding(tgt) * self.scale
x = self.pos_encoding(x)
for layer in self.layers:
x, _ = layer(x, enc_output, src_mask, tgt_mask)
return self.norm(x)
5. Mask机制¶
5.1 Padding Mask¶

屏蔽填充位置,防止模型关注无意义的 <pad> token:
def create_padding_mask(seq, pad_idx=0):
"""创建 Padding Mask"""
# seq: (batch, seq_len)
mask = (seq != pad_idx).unsqueeze(1).unsqueeze(2)
# mask: (batch, 1, 1, seq_len) — 可以广播到 (batch, heads, seq_q, seq_k)
return mask
5.2 Look-ahead Mask(因果掩码)¶
防止解码器"偷看"未来的token:
def create_look_ahead_mask(size):
"""创建因果掩码(上三角全为 0)"""
mask = torch.triu(torch.ones(size, size), diagonal=1) == 0
# True 表示可以看到,False 表示屏蔽
return mask.unsqueeze(0).unsqueeze(0) # (1, 1, size, size)
def create_decoder_mask(tgt, pad_idx=0):
"""解码器掩码 = Padding Mask AND Look-ahead Mask"""
padding_mask = create_padding_mask(tgt, pad_idx) # (batch, 1, 1, tgt_len)
look_ahead = create_look_ahead_mask(tgt.size(1)).to(tgt.device) # (1, 1, tgt_len, tgt_len)
combined_mask = padding_mask & look_ahead
return combined_mask
6. 残差连接与LayerNorm¶
6.1 Pre-Norm vs Post-Norm¶
# Post-Norm(原始 Transformer)
# x = LayerNorm(x + Sublayer(x))
# Pre-Norm(现代常用,训练更稳定)
# x = x + Sublayer(LayerNorm(x))
class PreNormEncoderLayer(nn.Module):
"""Pre-Norm 编码器层"""
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super().__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.ffn = FeedForward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask=None):
# Pre-Norm: x + Sublayer(Norm(x))
normed = self.norm1(x)
attn_out, weights = self.self_attn(normed, normed, normed, mask)
x = x + self.dropout(attn_out)
normed = self.norm2(x)
ffn_out = self.ffn(normed)
x = x + self.dropout(ffn_out)
return x, weights
2.7 GQA(Grouped-Query Attention)¶
Ainslie et al.(2023)提出的 GQA,是 MQA(Multi-Query Attention)和 MHA(Multi-Head Attention)的折中方案:
核心思想:将查询头分组,每组共享相同的 Key 和 Value
| 类型 | Q/K/V 数量 | 参数量 | 性能 | 适用场景 |
|---|---|---|---|---|
| MHA | N/N/N | 大 | 最好 | 通用场景 |
| MQA | N/1/1 | 小 | 较差 | 长文本生成 |
| GQA | N/G/G | 中等 | 接近MHA | 大模型推理 |
GQA 的优势: - 推理加速:KV Cache 大幅减少,内存占用降低 - 吞吐量提升:单卡支持更多并发请求 - 质量损失小:相比 MQA,性能下降可忽略
class GroupedQueryAttention(nn.Module):
"""Grouped-Query Attention"""
def __init__(self, d_model, num_heads, num_kv_heads=None, dropout=0.1):
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.num_kv_heads = num_kv_heads or num_heads // 4 # 默认4:1分组
self.head_dim = d_model // num_heads
self.q_proj = nn.Linear(d_model, d_model)
self.k_proj = nn.Linear(d_model, d_model * self.num_kv_heads // num_heads)
self.v_proj = nn.Linear(d_model, d_model * self.num_kv_heads // num_heads)
self.out_proj = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
self.scale = self.head_dim ** -0.5
def forward(self, x, mask=None):
batch_size, seq_len, _ = x.shape
# Q: (batch, num_heads, seq_len, head_dim)
# view将(B,S,d_model)拆为(B,S,heads,d_k),transpose(1,2)交换S和heads得(B,heads,S,d_k)便于并行计算各头注意力
q = self.q_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
# K, V: (batch, num_kv_heads, seq_len, head_dim) — GQA用更少的KV头节省显存
k = self.k_proj(x).view(batch_size, seq_len, self.num_kv_heads, self.head_dim).transpose(1, 2)
v = self.v_proj(x).view(batch_size, seq_len, self.num_kv_heads, self.head_dim).transpose(1, 2)
# 将 K, V 重复到 num_heads
# 例如:num_heads=32, num_kv_heads=8,则每个 K/V 头重复 4 次
k = k.repeat_interleave(self.num_heads // self.num_kv_heads, dim=1)
v = v.repeat_interleave(self.num_heads // self.num_kv_heads, dim=1)
# 计算注意力
attn = (q @ k.transpose(-2, -1)) * self.scale
if mask is not None:
attn = attn.masked_fill(mask == 0, float('-inf'))
attn = attn.softmax(dim=-1)
attn = self.dropout(attn)
# 输出
out = attn @ v
out = out.transpose(1, 2).contiguous().view(batch_size, seq_len, self.d_model)
return self.out_proj(out)
💡 应用:GQA 被广泛用于现代 LLM,如 LLaMA ⅔、Qwen 2/2.5、DeepSeek 系列等,是实现高效推理的关键技术之一。
7. 从零实现完整Transformer¶
class Transformer(nn.Module):
"""完整的 Transformer 模型"""
def __init__(self, src_vocab_size, tgt_vocab_size, d_model=512, num_heads=8,
d_ff=2048, num_encoder_layers=6, num_decoder_layers=6,
max_len=5000, dropout=0.1, pad_idx=0):
super().__init__()
self.pad_idx = pad_idx
# 编码器
self.encoder = TransformerEncoder(
src_vocab_size, d_model, num_heads, d_ff,
num_encoder_layers, max_len, dropout
)
# 解码器
self.decoder = TransformerDecoder(
tgt_vocab_size, d_model, num_heads, d_ff,
num_decoder_layers, max_len, dropout
)
# 输出投影
self.output_proj = nn.Linear(d_model, tgt_vocab_size)
# 初始化参数
self._init_parameters()
def _init_parameters(self):
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
def make_src_mask(self, src):
return create_padding_mask(src, self.pad_idx)
def make_tgt_mask(self, tgt):
return create_decoder_mask(tgt, self.pad_idx)
def forward(self, src, tgt):
"""
src: (batch, src_len) 源序列
tgt: (batch, tgt_len) 目标序列(训练时右移一位)
"""
src_mask = self.make_src_mask(src)
tgt_mask = self.make_tgt_mask(tgt)
# 编码
enc_output = self.encoder(src, src_mask)
# 解码
dec_output = self.decoder(tgt, enc_output, src_mask, tgt_mask)
# 输出投影
logits = self.output_proj(dec_output)
return logits
@torch.no_grad() # 装饰器:推理时禁用梯度计算,节省显存并加速
def greedy_decode(self, src, max_len=50, bos_idx=2, eos_idx=3):
"""贪心解码"""
self.eval() # eval()开启评估模式(关闭Dropout等)
src_mask = self.make_src_mask(src)
enc_output = self.encoder(src, src_mask)
batch_size = src.size(0)
tgt = torch.full((batch_size, 1), bos_idx, dtype=torch.long, device=src.device)
for _ in range(max_len):
tgt_mask = self.make_tgt_mask(tgt)
dec_output = self.decoder(tgt, enc_output, src_mask, tgt_mask)
logits = self.output_proj(dec_output[:, -1:])
next_token = logits.argmax(dim=-1)
tgt = torch.cat([tgt, next_token], dim=1)
if (next_token == eos_idx).all():
break
return tgt
# ===== 测试 =====
model = Transformer(
src_vocab_size=10000,
tgt_vocab_size=8000,
d_model=512,
num_heads=8,
d_ff=2048,
num_encoder_layers=6,
num_decoder_layers=6
)
src = torch.randint(4, 10000, (2, 30)) # batch=2, src_len=30
tgt = torch.randint(4, 8000, (2, 25)) # batch=2, tgt_len=25
logits = model(src, tgt)
print(f"模型输出: {logits.shape}") # (2, 25, 8000)
total_params = sum(p.numel() for p in model.parameters())
print(f"总参数量: {total_params:,}")
# 贪心解码
decoded = model.greedy_decode(src, max_len=30)
print(f"解码输出: {decoded.shape}")
8. 训练细节¶
8.1 学习率调度(原始论文)¶
class TransformerLRScheduler:
def __init__(self, optimizer, d_model, warmup_steps=4000):
self.optimizer = optimizer
self.d_model = d_model
self.warmup_steps = warmup_steps
self.step_num = 0
def step(self):
self.step_num += 1
lr = self.d_model ** (-0.5) * min(
self.step_num ** (-0.5),
self.step_num * self.warmup_steps ** (-1.5)
)
for pg in self.optimizer.param_groups:
pg['lr'] = lr
return lr
8.2 完整训练循环¶
def train_transformer(model, train_loader, epochs=30, device='cuda'):
model = model.to(device) # .to(device)将数据移至GPU/CPU
optimizer = torch.optim.Adam(model.parameters(), lr=0, betas=(0.9, 0.98), eps=1e-9)
scheduler = TransformerLRScheduler(optimizer, model.encoder.scale ** 2)
criterion = nn.CrossEntropyLoss(ignore_index=0, label_smoothing=0.1)
for epoch in range(epochs):
model.train() # train()开启训练模式
total_loss = 0
for src, tgt in train_loader:
src, tgt = src.to(device), tgt.to(device)
tgt_input = tgt[:, :-1] # 解码器输入(去掉最后一个token)
tgt_output = tgt[:, 1:] # 期望输出(去掉第一个token)
logits = model(src, tgt_input)
loss = criterion(
logits.reshape(-1, logits.size(-1)), # reshape重塑张量形状
tgt_output.reshape(-1)
)
optimizer.zero_grad() # 清零梯度,防止梯度累积
loss.backward() # 反向传播计算梯度
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step() # 根据梯度更新模型参数
scheduler.step()
total_loss += loss.item() # .item()将单元素张量转为Python数值
avg_loss = total_loss / len(train_loader)
print(f"Epoch {epoch+1}: Loss = {avg_loss:.4f}, LR = {optimizer.param_groups[0]['lr']:.6f}")
9. 练习与自我检查¶
练习题¶
- 从零实现:不参考代码,独立实现一个完整的 Transformer。
- 位置编码对比:分别使用正弦、可学习、RoPE 位置编码训练同一任务,对比效果。
- Pre-Norm vs Post-Norm:实验对比两者的训练稳定性和最终性能。
- 翻译任务:用你实现的 Transformer 在 Multi30k 数据集上训练德英翻译。
- 参数分析:改变 \(d_{model}\), \(h\), \(d_{ff}\), \(N\),观察对性能和效率的影响。
自我检查清单¶
- 能画出完整的 Transformer 架构图
- 理解为什么需要位置编码
- 能推导正弦位置编码的公式
- 了解 RoPE 和 ALiBi 的核心思想
- 能实现 Padding Mask 和 Look-ahead Mask
- 理解 Pre-Norm 和 Post-Norm 的区别
- 能从零实现完整的 Transformer 模型
- 理解 Transformer 的学习率调度策略
附录:现代Transformer优化技术汇总¶
A.1 归一化技术演进¶
| 技术 | 提出时间 | 特点 | 应用模型 |
|---|---|---|---|
| LayerNorm | 2016 | 计算均值和方差 | BERT, GPT-½ |
| RMSNorm | 2019 | 只计算RMS,更简洁 | LLaMA, Qwen, DeepSeek |
| Pre-Norm | 2020 | Norm在子层之前 | GPT-3, PaLM |
| Post-Norm | 2017 | Norm在子层之后 | 原始Transformer |
A.2 注意力优化技术¶
| 技术 | 提出时间 | 核心思想 | 优势 |
|---|---|---|---|
| Multi-Head Attention | 2017 | 多个注意力头并行 | 捕捉不同特征 |
| MQA | 2019 | 所有头共享K/V | 推理快,质量下降 |
| GQA | 2023 | 分组共享K/V | 平衡性能和效率 |
| FlashAttention | 2022 | IO感知,分块计算 | 大幅加速长序列 |
| PagedAttention | 2023 | KV Cache分页 | vLLM核心优化 |
A.3 位置编码技术¶
| 技术 | 提出时间 | 类型 | 优势 | 应用 |
|---|---|---|---|---|
| Sinusoidal PE | 2017 | 绝对位置 | 可外推 | 原始Transformer |
| Learned PE | 2018 | 可学习绝对位置 | 简单有效 | BERT, GPT |
| RoPE | 2021 | 相对位置 | 长文本效果好 | LLaMA, PaLM |
| ALiBi | 2022 | 注意力偏置 | 可外推 | BLOOM |
A.4 激活函数¶
| 技术 | 提出时间 | 公式 | 特点 |
|---|---|---|---|
| ReLU | 2012 | max(0, x) | 简单,但死神经元 |
| GELU | 2016 | xΦ(x) | 平滑,GPT-3使用 |
| SwiGLU | 2020 | Swish(x)·(xW) | PaLM, LLaMA使用 |
| GeGLU | 2020 | GELU(x)·(xW) | 训练稳定 |
💡 趋势:现代 LLM 的标准配置是 RoPE + RMSNorm + GQA + SwiGLU/GeGLU,这些技术的组合实现了性能和效率的最佳平衡。
更新说明: - 最后更新时间:2026年2月 - 新增内容: - RMSNorm 归一化技术详解 - GQA(Grouped-Query Attention)完整实现 - 现代Transformer优化技术汇总附录 - 数据来源:相关论文和开源模型实现
下一篇: 03-视觉Transformer