02-经典CNN架构¶
📌 章节定位:本文档隶属于深度学习教程体系,侧重CNN架构设计的理论基础与创新原理。 - 本文档重点:架构演进的理论动因、核心创新点的数学原理(如残差连接、Inception模块设计思想)、网络深度与宽度的权衡理论 - 应用实践方向:如需了解CNN架构在图像分类、目标检测等CV任务中的实际应用、预训练模型调用、迁移学习实战等内容,请参考 计算机视觉/06-经典CNN架构.md
学习时间: 约8-10小时 难度级别: ⭐⭐⭐⭐ 中高级 前置知识: 卷积神经网络基础、PyTorch 学习目标: 掌握经典CNN架构的核心思想、创新点和PyTorch实现
目录¶
- 1. CNN架构演进概览
- 2. LeNet-5
- 3. AlexNet
- 4. VGGNet
- 5. GoogLeNet(Inception)
- 6. ResNet
- 7. DenseNet
- 8. SENet
- 9. EfficientNet
- 10. MobileNet
- 11. 架构对比总结
- 12. 练习与自我检查
1. CNN架构演进概览¶
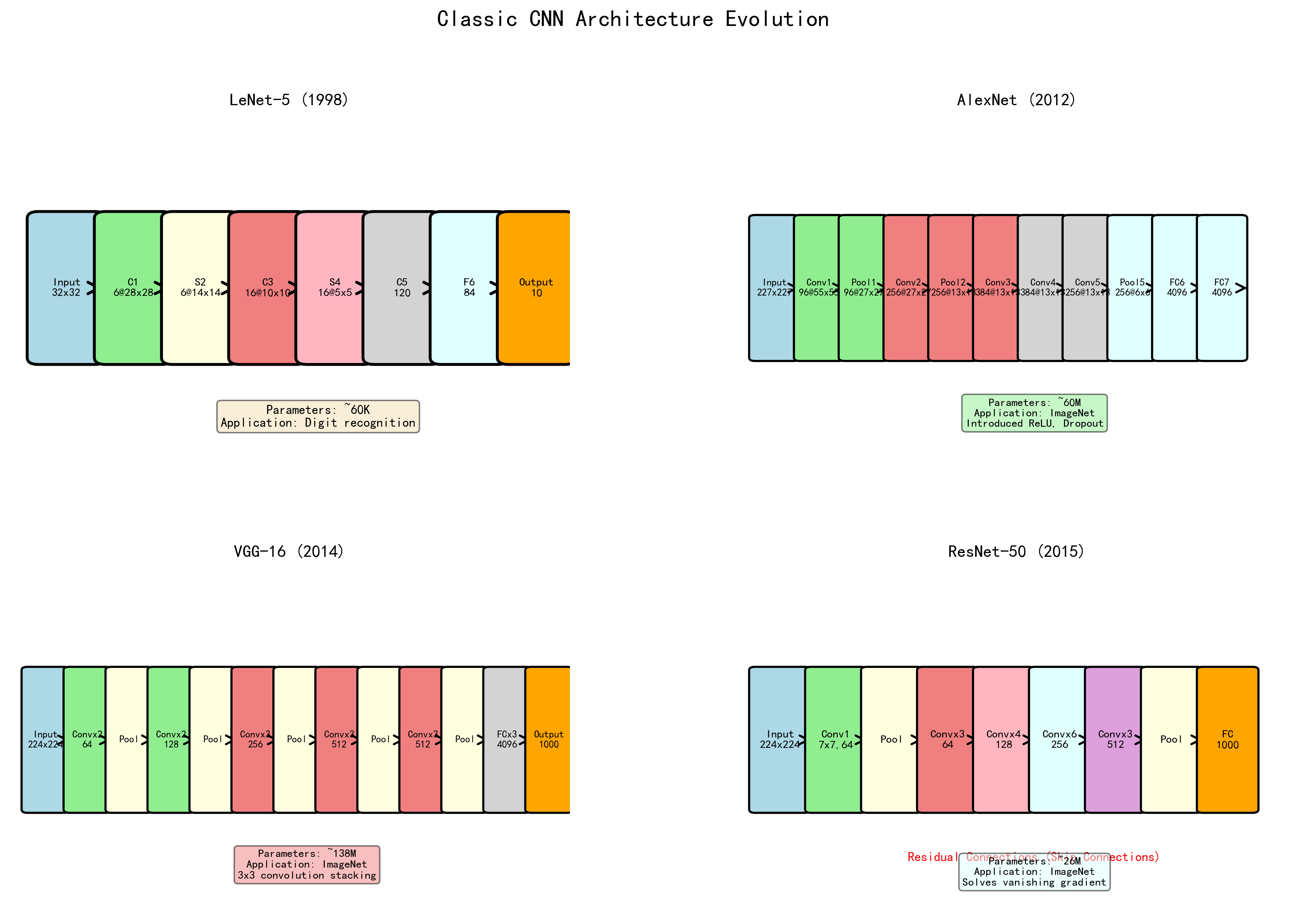
LeNet(1998) → AlexNet(2012) → VGG(2014) → GoogLeNet(2014) → ResNet(2015)
↓
MobileNet(2017) ← EfficientNet(2019) ← SENet(2017) ← DenseNet(2017)
| 架构 | 年份 | ImageNet Top-5 | 深度 | 关键创新 |
|---|---|---|---|---|
| AlexNet | 2012 | 15.3% | 8 | ReLU、Dropout、GPU训练 |
| VGG-16 | 2014 | 7.3% | 16 | 小卷积核堆叠 |
| GoogLeNet | 2014 | 6.7% | 22 | Inception模块 |
| ResNet-152 | 2015 | 3.6%(集成) | 152 | 残差连接 |
| DenseNet | 2017 | - | 121+ | 密集连接 |
| SENet | 2017 | 2.3% | - | 通道注意力 |
| EfficientNet | 2019 | 2.9% | - | 复合缩放 |
2. LeNet-5¶

核心思想¶
LeCun et al.(1998)设计了第一个成功的CNN,用于手写数字识别。
架构¶
输入 → Conv(5×5) → Pool → Conv(5×5) → Pool → FC → FC → 输出
PyTorch 实现¶
import torch
import torch.nn as nn
class LeNet5(nn.Module): # 继承nn.Module定义神经网络层
"""LeNet-5: 经典CNN的开山之作(适用于28×28 MNIST输入)"""
def __init__(self, num_classes=10): # __init__构造方法,创建对象时自动调用
super().__init__() # super()调用父类方法
self.features = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2), # (1,28,28) → (6,28,28)
nn.Tanh(),
nn.AvgPool2d(kernel_size=2, stride=2), # → (6,14,14)
nn.Conv2d(6, 16, kernel_size=5), # → (16,10,10)
nn.Tanh(),
nn.AvgPool2d(kernel_size=2, stride=2), # → (16,5,5)
)
self.classifier = nn.Sequential(
nn.Linear(16 * 5 * 5, 120),
nn.Tanh(),
nn.Linear(120, 84),
nn.Tanh(),
nn.Linear(84, num_classes),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
3. AlexNet¶

核心思想¶
Krizhevsky et al.(2012)在 ImageNet 上取得突破性成绩,开启深度学习时代。
关键创新¶
- ReLU激活: 替代 Sigmoid/Tanh,缓解梯度消失,训练速度提升6倍
- Dropout: 首次在大规模网络中使用
- 数据增强: 随机裁剪、翻转、PCA Color Augmentation
- GPU训练: 首次利用双GPU并行训练
- Local Response Normalization(LRN): 局部响应归一化(后被BN取代)
class AlexNet(nn.Module):
"""AlexNet: 深度学习时代的开端"""
def __init__(self, num_classes=1000):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=2), # → (96,55,55)
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # → (96,27,27)
nn.Conv2d(96, 256, kernel_size=5, padding=2), # → (256,27,27)
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # → (256,13,13)
nn.Conv2d(256, 384, kernel_size=3, padding=1), # → (384,13,13)
nn.ReLU(inplace=True),
nn.Conv2d(384, 384, kernel_size=3, padding=1), # → (384,13,13)
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1), # → (256,13,13)
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # → (256,6,6)
)
self.classifier = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), 256 * 6 * 6)
x = self.classifier(x)
return x
4. VGGNet¶
核心思想¶
Simonyan & Zisserman(2014)证明了网络深度对性能的重要性。用多个 \(3 \times 3\) 卷积替代大卷积核。
关键创新¶
- 两个 \(3 \times 3\) 卷积等效于一个 \(5 \times 5\) 的感受野,但参数更少(\(2 \times 9C^2 < 25C^2\))
- 三个 \(3 \times 3\) 卷积等效于一个 \(7 \times 7\) 的感受野(\(3 \times 9C^2 = 27C^2 < 49C^2\))
- 更多卷积层 = 更多非线性 = 更强的表达能力
📝 注意:原始VGG论文(Simonyan & Zisserman, 2014)不使用BatchNorm。下面的实现是后来加入BN的改进版本(VGG-BN),在现代实践中更常用。原版VGG仅使用Conv+ReLU。
class VGG(nn.Module):
"""VGG-BN网络(带BatchNorm的改进版本)"""
def __init__(self, features, num_classes=1000):
super().__init__()
self.features = features
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
def make_vgg_layers(cfg):
"""根据配置构建VGG特征提取层"""
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers.append(nn.MaxPool2d(kernel_size=2, stride=2))
else:
layers.extend([
nn.Conv2d(in_channels, v, kernel_size=3, padding=1),
nn.BatchNorm2d(v),
nn.ReLU(inplace=True)
])
in_channels = v
return nn.Sequential(*layers)
# VGG-16 配置
vgg16_cfg = [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M']
vgg16 = VGG(make_vgg_layers(vgg16_cfg), num_classes=1000)
5. GoogLeNet(Inception)¶

核心思想¶
Szegedy et al.(2015)提出 Inception 模块,在同一层中并行使用不同大小的卷积核,让网络自动选择最佳尺度。
关键创新¶
- Inception 模块: 并行使用 \(1 \times 1\)、\(3 \times 3\)、\(5 \times 5\) 卷积和 \(3 \times 3\) MaxPool
- \(1 \times 1\) 卷积降维: 大幅减少计算量("bottleneck"设计)
- 辅助分类器: 在中间层添加辅助损失,缓解梯度消失
- 全局平均池化: 替代全连接层,减少参数
class InceptionModule(nn.Module):
"""Inception 模块"""
def __init__(self, in_channels, ch1x1, ch3x3_reduce, ch3x3,
ch5x5_reduce, ch5x5, pool_proj):
super().__init__()
# 分支1: 1×1 卷积
self.branch1 = nn.Sequential(
nn.Conv2d(in_channels, ch1x1, kernel_size=1),
nn.BatchNorm2d(ch1x1),
nn.ReLU(inplace=True)
)
# 分支2: 1×1 → 3×3
self.branch2 = nn.Sequential(
nn.Conv2d(in_channels, ch3x3_reduce, kernel_size=1),
nn.BatchNorm2d(ch3x3_reduce),
nn.ReLU(inplace=True),
nn.Conv2d(ch3x3_reduce, ch3x3, kernel_size=3, padding=1),
nn.BatchNorm2d(ch3x3),
nn.ReLU(inplace=True)
)
# 分支3: 1×1 → 5×5
self.branch3 = nn.Sequential(
nn.Conv2d(in_channels, ch5x5_reduce, kernel_size=1),
nn.BatchNorm2d(ch5x5_reduce),
nn.ReLU(inplace=True),
nn.Conv2d(ch5x5_reduce, ch5x5, kernel_size=5, padding=2),
nn.BatchNorm2d(ch5x5),
nn.ReLU(inplace=True)
)
# 分支4: MaxPool → 1×1
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels, pool_proj, kernel_size=1),
nn.BatchNorm2d(pool_proj),
nn.ReLU(inplace=True)
)
def forward(self, x):
return torch.cat([
self.branch1(x),
self.branch2(x),
self.branch3(x),
self.branch4(x)
], dim=1) # 在通道维度拼接
# 使用示例
inception = InceptionModule(192, 64, 96, 128, 16, 32, 32)
x = torch.randn(1, 192, 28, 28)
print(f"Inception 输出: {inception(x).shape}") # (1, 256, 28, 28) → 64+128+32+32=256
6. ResNet¶

核心思想¶
He et al.(2016)提出残差学习(Residual Learning),使得训练极深网络成为可能。
关键创新 — 残差连接¶
问题: 更深的网络反而性能更差(degradation problem),不是过拟合,而是优化困难。
解决: 让网络学习残差映射 \(F(x) = H(x) - x\),而非直接学习 \(H(x)\):
为什么有效: - 如果恒等映射是最优的,学习 \(F(x) = 0\) 比学习 \(H(x) = x\) 容易得多 - 梯度可以通过捷径(shortcut)直接回传,缓解梯度消失 - 从集成学习角度看,ResNet 相当于许多不同深度的子网络的隐式集成
Bottleneck 设计¶
对于较深的 ResNet(50/101/152),使用 Bottleneck 结构减少计算量:
\(1 \times 1\) 降维 → \(3 \times 3\) 卷积 → \(1 \times 1\) 升维
class BasicBlock(nn.Module):
"""ResNet 基本残差块(用于 ResNet-18/34)"""
expansion = 1
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super().__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, 3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, 3, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.downsample = downsample
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
identity = x
out = self.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
if self.downsample is not None:
identity = self.downsample(x)
out += identity # 残差连接!
out = self.relu(out)
return out
class Bottleneck(nn.Module):
"""ResNet Bottleneck 残差块(用于 ResNet-50/101/152)"""
expansion = 4
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super().__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, 1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, 3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.conv3 = nn.Conv2d(out_channels, out_channels * self.expansion, 1, bias=False)
self.bn3 = nn.BatchNorm2d(out_channels * self.expansion)
self.downsample = downsample
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
identity = x
out = self.relu(self.bn1(self.conv1(x)))
out = self.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
"""完整的 ResNet 实现"""
def __init__(self, block, layers, num_classes=1000):
super().__init__()
self.in_channels = 64
# Stem
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# Residual layers
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
# 权重初始化
for m in self.modules():
if isinstance(m, nn.Conv2d): # isinstance检查对象类型
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def _make_layer(self, block, out_channels, num_blocks, stride=1):
downsample = None
if stride != 1 or self.in_channels != out_channels * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channels, out_channels * block.expansion, 1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * block.expansion),
)
layers = [block(self.in_channels, out_channels, stride, downsample)]
self.in_channels = out_channels * block.expansion
for _ in range(1, num_blocks):
layers.append(block(self.in_channels, out_channels))
return nn.Sequential(*layers)
def forward(self, x):
x = self.relu(self.bn1(self.conv1(x)))
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
# 构建不同深度的 ResNet
def resnet18(num_classes=1000): return ResNet(BasicBlock, [2, 2, 2, 2], num_classes)
def resnet34(num_classes=1000): return ResNet(BasicBlock, [3, 4, 6, 3], num_classes)
def resnet50(num_classes=1000): return ResNet(Bottleneck, [3, 4, 6, 3], num_classes)
def resnet101(num_classes=1000): return ResNet(Bottleneck, [3, 4, 23, 3], num_classes)
def resnet152(num_classes=1000): return ResNet(Bottleneck, [3, 8, 36, 3], num_classes)
model = resnet50(num_classes=10)
x = torch.randn(2, 3, 224, 224)
print(f"ResNet-50 输出: {model(x).shape}")
print(f"参数量: {sum(p.numel() for p in model.parameters()):,}")
训练技巧¶
- 使用 Kaiming 初始化
- BN 层 \(\gamma\) 在残差块的最后一层初始化为 0
- 使用 Warmup + Cosine/StepLR 学习率调度
- Label Smoothing
7. DenseNet¶

核心思想¶
Huang et al.(2017)提出密集连接 — 每一层都与前面所有层连接,最大化特征重用。
class DenseLayer(nn.Module):
"""DenseNet 密集层"""
def __init__(self, in_channels, growth_rate, bn_size=4):
super().__init__()
self.layer = nn.Sequential(
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels, bn_size * growth_rate, 1, bias=False),
nn.BatchNorm2d(bn_size * growth_rate),
nn.ReLU(inplace=True),
nn.Conv2d(bn_size * growth_rate, growth_rate, 3, padding=1, bias=False),
)
def forward(self, x):
new_features = self.layer(x)
return torch.cat([x, new_features], dim=1)
class DenseBlock(nn.Module):
"""DenseNet 密集块"""
def __init__(self, num_layers, in_channels, growth_rate):
super().__init__()
layers = []
for i in range(num_layers):
layers.append(DenseLayer(in_channels + i * growth_rate, growth_rate))
self.block = nn.Sequential(*layers)
def forward(self, x):
return self.block(x)
class Transition(nn.Module):
"""DenseNet 过渡层(降维+下采样)"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.layer = nn.Sequential(
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.AvgPool2d(2, stride=2),
)
def forward(self, x):
return self.layer(x)
8. SENet¶
核心思想¶
Hu et al.(2018)提出 Squeeze-and-Excitation(SE)模块 — 通道注意力机制,自适应地重新校准各通道的重要性。
- Squeeze: 全局平均池化,将 \((C, H, W)\) 压缩为 \((C, 1, 1)\)
- Excitation: 两个全连接层学习通道权重
- Scale: 用学到的权重重新缩放各通道
class SEBlock(nn.Module):
"""Squeeze-and-Excitation 模块"""
def __init__(self, channels, reduction=16):
super().__init__()
self.squeeze = nn.AdaptiveAvgPool2d(1)
self.excitation = nn.Sequential(
nn.Linear(channels, channels // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channels // reduction, channels, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
# Squeeze
y = self.squeeze(x).view(b, c) # 链式调用,连续执行多个方法 # squeeze去除大小为1的维度
# Excitation
y = self.excitation(y).view(b, c, 1, 1)
# Scale
return x * y.expand_as(x)
# SE-ResNet Block
class SEBasicBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, downsample=None, reduction=16):
super().__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, 3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, 3, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.se = SEBlock(out_channels, reduction)
self.downsample = downsample
def forward(self, x):
identity = x
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out = self.se(out) # SE 注意力
if self.downsample:
identity = self.downsample(x)
out += identity
return F.relu(out)
9. EfficientNet¶
核心思想¶
Tan & Le(2019)提出复合缩放(Compound Scaling)— 同时缩放网络的宽度、深度和分辨率。
缩放公式: - 深度: \(d = \alpha^\phi\) - 宽度: \(w = \beta^\phi\) - 分辨率: \(r = \gamma^\phi\)
约束: \(\alpha \cdot \beta^2 \cdot \gamma^2 \approx 2\)
EfficientNet-B0 的基础架构使用 MBConv(Mobile Inverted Bottleneck) 块:
class MBConv(nn.Module):
"""Mobile Inverted Bottleneck Convolution(EfficientNet 基础块)"""
def __init__(self, in_channels, out_channels, expand_ratio, stride, kernel_size=3, se_ratio=0.25):
super().__init__()
self.stride = stride
self.use_residual = (stride == 1 and in_channels == out_channels)
hidden_dim = in_channels * expand_ratio
layers = []
# 扩展(如果 expand_ratio > 1)
if expand_ratio != 1:
layers.extend([
nn.Conv2d(in_channels, hidden_dim, 1, bias=False),
nn.BatchNorm2d(hidden_dim),
nn.SiLU(inplace=True), # Swish 激活函数
])
# 深度卷积
layers.extend([
nn.Conv2d(hidden_dim, hidden_dim, kernel_size, stride=stride,
padding=kernel_size//2, groups=hidden_dim, bias=False),
nn.BatchNorm2d(hidden_dim),
nn.SiLU(inplace=True),
])
# SE 注意力
se_channels = max(1, int(in_channels * se_ratio))
layers.extend([
SEBlock(hidden_dim, reduction=hidden_dim // se_channels),
])
# 逐点卷积
layers.extend([
nn.Conv2d(hidden_dim, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
])
self.block = nn.Sequential(*layers)
def forward(self, x):
if self.use_residual:
return x + self.block(x)
return self.block(x)
10. MobileNet¶
核心思想¶
Howard et al.(2017)为移动端设备设计的轻量级网络,核心是深度可分离卷积。
MobileNetV2 的倒残差块(Inverted Residual Block)¶
与 ResNet 的 Bottleneck(宽→窄→宽)相反,MobileNetV2 使用窄→宽→窄的结构,在高维空间中进行深度卷积:
class InvertedResidual(nn.Module):
"""MobileNetV2 倒残差块"""
def __init__(self, in_channels, out_channels, stride, expand_ratio):
super().__init__()
self.use_residual = (stride == 1 and in_channels == out_channels)
hidden_dim = int(in_channels * expand_ratio)
layers = []
if expand_ratio != 1:
# 1×1 扩展
layers.extend([
nn.Conv2d(in_channels, hidden_dim, 1, bias=False),
nn.BatchNorm2d(hidden_dim),
nn.ReLU6(inplace=True),
])
layers.extend([
# 3×3 深度卷积
nn.Conv2d(hidden_dim, hidden_dim, 3, stride=stride, padding=1,
groups=hidden_dim, bias=False),
nn.BatchNorm2d(hidden_dim),
nn.ReLU6(inplace=True),
# 1×1 压缩 (线性激活,不用 ReLU)
nn.Conv2d(hidden_dim, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
])
self.block = nn.Sequential(*layers)
def forward(self, x):
if self.use_residual:
return x + self.block(x)
return self.block(x)
class MobileNetV2(nn.Module):
"""MobileNetV2"""
def __init__(self, num_classes=1000, width_mult=1.0):
super().__init__()
# (expand_ratio, out_channels, num_blocks, stride)
settings = [
[1, 16, 1, 1],
[6, 24, 2, 2],
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1],
]
in_channels = int(32 * width_mult)
features = [nn.Sequential(
nn.Conv2d(3, in_channels, 3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(in_channels),
nn.ReLU6(inplace=True)
)]
for t, c, n, s in settings:
out_channels = int(c * width_mult)
for i in range(n):
stride = s if i == 0 else 1
features.append(InvertedResidual(in_channels, out_channels, stride, t))
in_channels = out_channels
last_channels = int(1280 * width_mult)
features.append(nn.Sequential(
nn.Conv2d(in_channels, last_channels, 1, bias=False),
nn.BatchNorm2d(last_channels),
nn.ReLU6(inplace=True)
))
self.features = nn.Sequential(*features)
self.classifier = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Flatten(),
nn.Dropout(0.2),
nn.Linear(last_channels, num_classes),
)
def forward(self, x):
x = self.features(x)
x = self.classifier(x)
return x
11. 架构对比总结¶
| 架构 | 参数量 | Top-1 Acc | 核心创新 | 适用场景 |
|---|---|---|---|---|
| VGG-16 | 138M | 71.5% | 小核堆叠 | 特征提取 |
| GoogLeNet | 6.8M | 74.8% | Inception模块 | 多尺度特征 |
| ResNet-50 | 25.6M | 76.1% | 残差连接 | 通用backbone |
| DenseNet-121 | 8.0M | 74.4% | 密集连接 | 特征重用 |
| SENet | +少量 | +1~2% | 通道注意力 | 即插即用 |
| EfficientNet-B0 | 5.3M | 77.1% | 复合缩放 | 效率与精度平衡 |
| MobileNetV2 | 3.4M | 72.0% | 倒残差块 | 移动端部署 |
12. 练习与自我检查¶
练习题¶
- 从零实现 ResNet-18 并在 CIFAR-10 上训练。
- 在 ResNet 基础上添加 SE 模块,对比有无注意力的效果。
- 实现 Inception 中的并行分支模块,可视化不同分支学到的特征。
- 设计一个类 MobileNet 风格的轻量网络用于 FashionMNIST 分类。
- 比较 ResNet-50 和 DenseNet-121 在相同数据上的性能和显存占用。
自我检查清单¶
- 能清晰描述每种架构的核心思想和关键创新
- 理解残差连接为什么能训练更深的网络
- 能从零实现 ResNet 的 BasicBlock 和 Bottleneck
- 理解 \(1 \times 1\) 卷积的作用(降维、升维、通道混合)
- 能解释 DenseNet 的特征重用和梯度流优势
- 理解 SE 模块的通道注意力机制
- 了解 EfficientNet 的复合缩放策略
- 能根据任务需求选择合适的 CNN 架构
下一篇: 03-CNN实战与技巧