10-Transformer架构¶
学习时间: 约8-10小时 难度级别: ⭐⭐⭐⭐ 中高级 前置知识: 循环神经网络、注意力机制基础、线性代数 学习目标: 深入理解Transformer的数学原理,掌握自注意力、多头注意力、位置编码等核心组件,能从零实现Transformer
🎯 学习目标¶
- 理解从RNN到Transformer的演进动机
- 掌握自注意力机制(Self-Attention)的完整数学推导
- 理解多头注意力(Multi-Head Attention)的设计思想
- 掌握各种位置编码方案(正弦、可学习、RoPE)
- 深入理解Transformer编码器和解码器的完整结构
- 理解Pre-Norm与Post-Norm的区别
- 了解Vision Transformer (ViT) 如何将Transformer应用于视觉
- 理解BERT和GPT的架构选择差异
- 能用PyTorch从零实现Multi-Head Attention
- 了解注意力复杂度优化方向
目录¶
- 1. 从RNN到Transformer
- 2. 自注意力机制
- 3. 多头注意力
- 4. 位置编码
- 5. Transformer编码器
- 6. Transformer解码器
- 7. 完整Transformer架构
- 8. Pre-Norm vs Post-Norm
- 9. Vision Transformer
- 10. BERT与GPT的架构选择
- 11. PyTorch实现:从零实现Multi-Head Attention
- 12. 复杂度分析与优化
- 13. 练习与自我检查
1. 从RNN到Transformer¶
1.1 RNN的根本限制¶
尽管LSTM/GRU在很大程度上缓解了梯度消失问题,RNN家族仍有两个难以克服的局限:
- 无法并行:隐藏状态 \(\mathbf{h}_t\) 依赖 \(\mathbf{h}_{t-1}\),必须逐步计算,无法利用现代GPU的并行能力
- 长距离衰减:即使是LSTM,在序列长度超过几百步后,信息传递仍会逐步衰减
1.2 注意力的启示¶
Seq2Seq + Attention 证明了一件事:直接建立远距离连接比通过递推传递信息更高效。
那么一个自然的问题是:能否完全抛弃递推结构,只用注意力来建模序列?
1.3 Transformer的诞生¶
2017年,Vaswani等人提出了 "Attention Is All You Need",回答是 Yes。
Transformer的核心创新: - 用自注意力(Self-Attention)取代循环结构,让序列中每个位置都能直接关注所有其他位置 - 用位置编码补偿抛弃递推后丢失的位置信息 - 完全可并行化,训练速度远超RNN
这篇论文改变了整个AI领域的发展方向——BERT、GPT、ViT、Stable Diffusion等几乎所有现代AI模型都基于Transformer。
2. 自注意力机制¶

图注:自注意力机制——每个位置都能直接关注序列中所有其他位置
2.1 核心思想¶
给定一个序列 \((x_1, x_2, \ldots, x_n)\),自注意力让每个元素通过计算与其他所有元素的"相关性"来更新自己的表示。
直觉:在理解"The animal didn't cross the street because it was too tired"这句话时,自注意力机制可以让"it"直接关注到"animal",自动建立两者的关联。
2.2 Q/K/V 计算¶
对输入序列的每个位置 \(\mathbf{x}_i \in \mathbb{R}^{d_{\text{model}}}\),通过三个线性变换生成查询(Query)、键(Key)、值(Value):

图注:Q/K/V计算过程——输入通过三个不同的权重矩阵投影
其中 \(\mathbf{X} \in \mathbb{R}^{n \times d_{\text{model}}}\) 是输入矩阵,\(\mathbf{W}^Q, \mathbf{W}^K \in \mathbb{R}^{d_{\text{model}} \times d_k}\),\(\mathbf{W}^V \in \mathbb{R}^{d_{\text{model}} \times d_v}\)。
直觉理解: - Query(查询):当前位置"想要找什么" - Key(键):每个位置"提供的索引标签" - Value(值):每个位置"实际包含的内容"
注意力就是用Query去匹配所有的Key,根据匹配度加权求和所有的Value。
2.3 缩放点积注意力(Scaled Dot-Product Attention)¶

图注:缩放点积注意力计算流程——Q·K^T计算注意力分数,softmax归一化后加权求和V
分步拆解:
第一步:计算注意力分数矩阵
\(S_{ij}\) 表示位置 \(i\) 对位置 \(j\) 的关注程度(未归一化)。
第二步:缩放
为什么要除以 \(\sqrt{d_k}\)? 当 \(d_k\) 较大时,\(\mathbf{q}^T \mathbf{k}\) 的方差约为 \(d_k\)(假设Q和K的各分量独立同分布,均值0方差1),导致值很大,softmax输出接近one-hot(梯度极小)。除以 \(\sqrt{d_k}\) 将方差归一到1,使softmax输出更平滑,梯度更健康。
第三步:Softmax归一化
每行归一化为概率分布,\(A_{ij}\) 是位置 \(i\) 分配给位置 \(j\) 的注意力权重。
第四步:加权求和
每个位置的输出是所有位置Value的加权平均,权重就是注意力分数。
2.4 自注意力 vs 交叉注意力¶
- 自注意力(Self-Attention):Q、K、V来自同一个序列,序列内部互看
- 交叉注意力(Cross-Attention):Q来自一个序列(解码器),K和V来自另一个序列(编码器),实现序列间信息交换
3. 多头注意力¶

图注:多头注意力机制——多个注意力头并行计算,结果拼接
3.1 动机¶
单头注意力只能关注一种模式的关联。多头注意力让模型能同时从不同的表示子空间中捕获不同类型的关系。
例如处理"I love the cat because it is cute"时: - 第1个头可能关注语法关系("it" → "cat") - 第2个头可能关注语义关系("love" → "cute") - 第3个头可能关注局部上下文
3.2 数学公式¶
其中: - \(h\) 是头的数量(原论文 \(h=8\)) - \(d_k = d_v = d_{\text{model}} / h\)(每个头的维度) - \(\mathbf{W}_i^Q, \mathbf{W}_i^K \in \mathbb{R}^{d_{\text{model}} \times d_k}\) - \(\mathbf{W}_i^V \in \mathbb{R}^{d_{\text{model}} \times d_v}\) - \(\mathbf{W}^O \in \mathbb{R}^{h \cdot d_v \times d_{\text{model}}}\) — 输出投影矩阵
3.3 计算效率¶
虽然有 \(h\) 个头,但每个头的维度是 \(d_{\text{model}} / h\),所以总计算量与单头全维度注意力相当:
实际实现中,多头注意力通常通过一次大矩阵乘法+reshape来并行计算所有头,非常高效。
4. 位置编码¶
4.1 为什么需要位置编码¶
自注意力是集合运算(set operation),对输入的排列(permutation)不变:打乱输入顺序,输出只是对应打乱,不改变值。
但语言是有序的——"dog bites man" 和 "man bites dog" 含义完全不同。因此需要显式注入位置信息。
4.2 正弦/余弦位置编码(Sinusoidal Positional Encoding)¶

图注:正弦位置编码——不同维度使用不同频率的正弦/余弦波
原始Transformer论文使用的固定位置编码:
其中 \(pos\) 是位置索引(0, 1, 2, ...),\(i\) 是维度索引。
设计思想: - 不同维度使用不同频率的正弦/余弦波(从高频到低频) - 每个位置有唯一的编码 - 相对位置关系可以通过线性变换表示:\(PE_{pos+k}\) 可以表示为 \(PE_{pos}\) 的线性函数 - 可外推到训练中未见过的序列长度
import math
class SinusoidalPositionalEncoding(nn.Module): # 继承nn.Module定义神经网络层
def __init__(self, d_model, max_len=5000, dropout=0.1): # __init__构造方法,创建对象时自动调用
super().__init__() # super()调用父类方法
self.dropout = nn.Dropout(dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # 链式调用,连续执行多个方法 # unsqueeze增加一个维度
div_term = torch.exp(torch.arange(0, d_model, 2).float() *
(-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0) # (1, max_len, d_model)
self.register_buffer('pe', pe)
def forward(self, x):
# x: (batch, seq_len, d_model)
x = x + self.pe[:, :x.size(1)]
return self.dropout(x)
4.3 可学习位置编码(Learned Positional Encoding)¶
直接将位置编码作为可训练的embedding:
class LearnedPositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=512, dropout=0.1):
super().__init__()
self.pos_embedding = nn.Embedding(max_len, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
positions = torch.arange(x.size(1), device=x.device).unsqueeze(0)
x = x + self.pos_embedding(positions)
return self.dropout(x)
BERT和GPT使用可学习位置编码,效果与正弦编码相当。缺点是不能外推到比训练时更长的序列。
4.4 旋转位置编码(RoPE, Rotary Position Embedding)¶

图注:RoPE旋转位置编码——通过旋转Q和K向量来编码相对位置信息
RoPE(Su et al., 2021)是目前大模型最流行的位置编码方案(LLaMA、Qwen、Mistral等均采用)。
核心思想:不是将位置信息加到输入上,而是通过旋转Q和K向量来编码位置信息。
对于query向量 \(\mathbf{q}\) 在位置 \(m\) 和key向量 \(\mathbf{k}\) 在位置 \(n\),RoPE确保它们的内积只依赖于相对位置 \(m-n\):
具体实现是将向量每两个维度分为一组,在每组上施加二维旋转:
其中 \(\theta_i = 10000^{-2i/d}\)。
RoPE的优势: - 天然编码相对位置信息 - 对长度具有更好的外推能力(配合NTK-aware scaling等技术) - 无额外参数 - 与注意力计算无缝结合
4.5 位置编码对比¶

图注:不同位置编码方案的比较——正弦编码、可学习编码和RoPE各有优劣
5. Transformer编码器¶

图注:Transformer编码器和解码器架构——交叉注意力连接两者
5.1 编码器层结构¶
每个编码器层(Encoder Layer)包含两个子层:
Encoder Layer:
输入 x
→ Multi-Head Self-Attention → Add & Norm → z
→ Feed-Forward Network → Add & Norm → 输出
5.2 Layer Normalization¶
其中 \(\mu\) 和 \(\sigma^2\) 是在特征维度上计算的均值和方差(与Batch Norm不同——Batch Norm在batch维度上计算)。
为什么用LayerNorm而不是BatchNorm? - 序列长度可变,batch中不同样本的时间步对不齐 - LayerNorm对每个样本独立归一化,不依赖batch统计量 - 在推理时行为一致(无train/eval区别)
5.3 残差连接¶
每个子层的输出都加上输入(跳跃连接),与ResNet思想相同:
残差连接确保梯度能直接回传,使训练深层Transformer成为可能。
5.4 前馈网络(FFN)¶
其中 \(\mathbf{W}_1 \in \mathbb{R}^{d_{\text{model}} \times d_{\text{ff}}}\),\(\mathbf{W}_2 \in \mathbb{R}^{d_{\text{ff}} \times d_{\text{model}}}\),通常 \(d_{\text{ff}} = 4 \times d_{\text{model}}\)。
原论文使用ReLU,现代模型更多使用GELU或SwiGLU。
FFN的作用:对每个位置独立地进行非线性变换,增加模型的表达能力。如果说注意力层负责"位置间交互",FFN就负责"位置内变换"。
5.5 完整编码器¶
编码器由 \(N\) 个相同的编码器层堆叠而成(原论文 \(N=6\)):
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model=512, nhead=8, d_ff=2048, dropout=0.1):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=True)
self.ffn = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(d_ff, d_model),
nn.Dropout(dropout),
)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, src_mask=None, src_key_padding_mask=None):
# Post-Norm: Norm在残差之后
attn_out, _ = self.self_attn(x, x, x, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)
x = self.norm1(x + self.dropout(attn_out))
ffn_out = self.ffn(x)
x = self.norm2(x + ffn_out)
return x
6. Transformer解码器¶
6.1 解码器层结构¶
每个解码器层包含三个子层:
Decoder Layer:
输入 y
→ Masked Multi-Head Self-Attention → Add & Norm
→ Multi-Head Cross-Attention (Q from decoder, K/V from encoder) → Add & Norm
→ Feed-Forward Network → Add & Norm → 输出
6.2 掩码自注意力(Masked Self-Attention)¶

图注:解码器中的因果掩码——上三角区域被屏蔽,防止信息泄露
在训练时,解码器是并行处理整个目标序列的。但在推理时,生成是自回归的(一个一个token生成)。为了让训练和推理行为一致,需要让位置 \(i\) 只能看到位置 \(\le i\) 的信息——通过因果掩码(Causal Mask)实现。
在softmax之前加上掩码:
\(-\infty\) 经过softmax后变为0,实现了信息屏蔽。
def generate_causal_mask(seq_len):
"""生成因果掩码:1=可注意, 0=屏蔽(与MHA的masked_fill(mask==0, -inf)配合使用)"""
return torch.tril(torch.ones(seq_len, seq_len))
# 示例
mask = generate_causal_mask(5)
# tensor([[1., 0., 0., 0., 0.],
# [1., 1., 0., 0., 0.],
# [1., 1., 1., 0., 0.],
# [1., 1., 1., 1., 0.],
# [1., 1., 1., 1., 1.]])
6.3 交叉注意力(Cross-Attention)¶

图注:交叉注意力机制——Query来自解码器,Key和Value来自编码器
解码器的第二个注意力子层执行交叉注意力: - Query来自解码器上一子层的输出 - Key和Value来自编码器的输出
这让解码器的每一步都能关注输入序列的所有位置,实现信息从编码器到解码器的传递。
7. 完整Transformer架构¶
Transformer架构¶
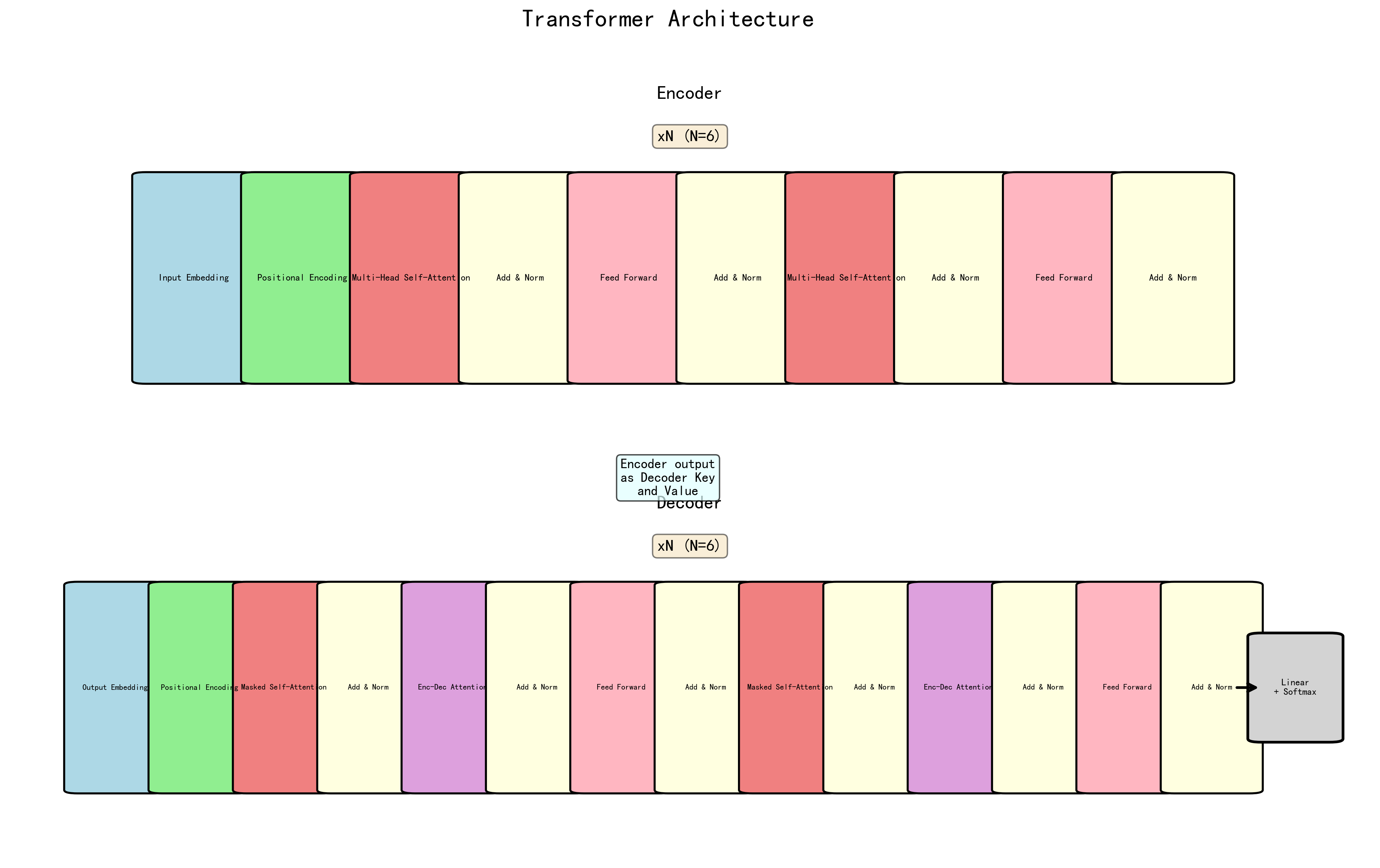
图注:Transformer完整架构——编码器-解码器结构
7.1 整体结构¶
输入序列 目标序列(右移一位)
↓ ↓
输入嵌入 + 位置编码 输出嵌入 + 位置编码
↓ ↓
┌──────────────┐ ┌──────────────┐
│ Encoder ×N │ │ Decoder ×N │
│ │───K,V──────→ │ │
└──────────────┘ └──────────────┘
↓
Linear + Softmax
↓
输出概率分布
7.2 原始Transformer超参数¶
| 超参数 | 值 |
|---|---|
| \(d_{\text{model}}\) | 512 |
| \(d_{\text{ff}}\) | 2048 |
| \(h\)(注意力头数) | 8 |
| \(d_k = d_v = d_{\text{model}} / h\) | 64 |
| 编码器层数 \(N\) | 6 |
| 解码器层数 \(N\) | 6 |
| Dropout | 0.1 |
| 总参数量 | ~65M |
7.3 训练技巧¶
Warm-up学习率调度(原论文使用):
先线性增加学习率,再按步数的逆平方根衰减。现代实践中常用Cosine Annealing或WSD调度器替代。
Label Smoothing:将目标分布中正确类别的概率从1平滑到 \(1 - \epsilon\)(如0.9),将 \(\epsilon\) 均分给其他类别,防止模型过度自信。
8. Pre-Norm vs Post-Norm¶
8.1 Post-Norm(原始Transformer)¶
LayerNorm在残差连接之后。需要精心的学习率warmup才能稳定训练。
8.2 Pre-Norm(现代主流)¶
LayerNorm在子层之前。
Pre-Norm的优势: - 训练更稳定,不需要warmup - 残差路径上没有归一化,梯度传播更顺畅 - 更容易训练深层模型
Pre-Norm的劣势: - 最终表示可能不够"归一化",通常在最后加一个额外的LayerNorm - 有研究表明同等深度下Post-Norm的表达能力略强
现代大模型几乎都使用Pre-Norm(GPT系列、LLaMA等)。
class PreNormEncoderLayer(nn.Module):
"""Pre-Norm Transformer编码器层"""
def __init__(self, d_model=512, nhead=8, d_ff=2048, dropout=0.1):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=True)
self.ffn = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(d_ff, d_model),
nn.Dropout(dropout),
)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
def forward(self, x, src_mask=None):
# Pre-Norm: 先归一化,再进入子层
attn_out, _ = self.self_attn(self.norm1(x), self.norm1(x), self.norm1(x), attn_mask=src_mask)
x = x + attn_out
x = x + self.ffn(self.norm2(x))
return x
9. Vision Transformer¶

图注:Vision Transformer架构——将图像分割为patch后送入Transformer编码器
9.1 ViT核心思想¶
Vision Transformer(Dosovitskiy et al., 2020)将Transformer直接应用于图像分类,证明了Transformer不仅限于NLP。
关键步骤:将图像分割为固定大小的 patch,将每个 patch 线性映射为一个向量(token),然后送入标准 Transformer 编码器。
9.2 图像 → 序列¶

图注:Patch Embedding——将图像分割为固定大小的patch并线性映射为向量
对于 \(H \times W \times C\) 的图像,使用 \(P \times P\) 大小的 patch:
- 将图像分割为 \(N = \frac{H \times W}{P^2}\) 个 patch
- 每个 patch 展平为 \(P^2 \times C\) 维向量
- 通过线性投影映射到 \(d_{\text{model}}\) 维
- 在序列前面加一个可学习的
[CLS]token - 加上位置编码
其中 \(\mathbf{E} \in \mathbb{R}^{(P^2 \cdot C) \times d_{\text{model}}}\) 是patch嵌入矩阵。
class PatchEmbedding(nn.Module):
"""将图像转化为patch序列"""
def __init__(self, img_size=224, patch_size=16, in_channels=3, embed_dim=768):
super().__init__()
self.num_patches = (img_size // patch_size) ** 2
# 用卷积实现patch分割+线性投影
self.proj = nn.Conv2d(in_channels, embed_dim,
kernel_size=patch_size, stride=patch_size)
def forward(self, x):
# x: (batch, 3, 224, 224)
x = self.proj(x) # (batch, embed_dim, 14, 14)
x = x.flatten(2) # (batch, embed_dim, 196)
x = x.transpose(1, 2) # (batch, 196, embed_dim)
return x
9.3 ViT的关键发现¶
- 数据量小时,ViT不如CNN(缺少CNN的归纳偏置:局部性和平移不变性)
- 数据量大时(JFT-300M等),ViT显著超越CNN
- DeiT等后续工作通过知识蒸馏和数据增强,使ViT在ImageNet上也能超越CNN
10. BERT与GPT的架构选择¶
10.1 BERT——编码器架构¶
BERT(Bidirectional Encoder Representations from Transformers) 只使用Transformer 编码器:
- 双向注意力:每个token可以看到整个序列(前后文)
- 预训练任务:
- MLM(Masked Language Modeling):随机遮住15%的token,模型预测被遮住的词
- NSP(Next Sentence Prediction):判断两个句子是否是连续的
- 适用场景:理解型任务(分类、NER、QA、句子相似度)
- 限制:不能直接用于文本生成(因为是双向的)
10.2 GPT——解码器架构¶
GPT(Generative Pre-trained Transformer) 只使用Transformer 解码器(去掉交叉注意力):
- 因果注意力(Causal/Masked Attention):每个token只能看到左边的token
- 预训练任务:自回归语言建模 — 预测下一个token
- 适用场景:生成型任务(文本生成、对话、代码生成)
- 优势:统一的"预测下一个token"范式,可通过scaling law持续提升
10.3 对比总结¶
| 特性 | BERT(编码器) | GPT(解码器) |
|---|---|---|
| 注意力方向 | 双向(全局可见) | 单向(因果掩码) |
| 预训练目标 | MLM + NSP | 自回归 LM |
| 擅长任务 | 理解(分类、抽取) | 生成(续写、对话) |
| 代表模型 | BERT, RoBERTa, DeBERTa | GPT-⅔/4, LLaMA, Qwen |
| 发展趋势 | 逐渐被decoder-only取代 | 当前大模型主流 |
现代趋势:Decoder-only架构(GPT式)通过提示(Prompting)和上下文学习(In-Context Learning)也能很好地完成理解型任务,因此成为大模型的主流选择。
11. PyTorch实现:从零实现Multi-Head Attention¶
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class MultiHeadAttention(nn.Module):
"""从零实现多头注意力机制"""
def __init__(self, d_model=512, num_heads=8, dropout=0.1):
super().__init__()
assert d_model % num_heads == 0, "d_model must be divisible by num_heads" # assert断言,条件为False时抛出异常
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads # 每个头的维度
# Q/K/V投影矩阵(可以合并为一个大矩阵提升效率)
self.W_q = nn.Linear(d_model, d_model, bias=False)
self.W_k = nn.Linear(d_model, d_model, bias=False)
self.W_v = nn.Linear(d_model, d_model, bias=False)
# 输出投影
self.W_o = nn.Linear(d_model, d_model, bias=False)
self.dropout = nn.Dropout(dropout)
self.scale = math.sqrt(self.d_k)
def split_heads(self, x, batch_size):
"""
将(batch, seq_len, d_model)拆分为(batch, num_heads, seq_len, d_k)
"""
x = x.view(batch_size, -1, self.num_heads, self.d_k)
return x.transpose(1, 2)
def scaled_dot_product_attention(self, Q, K, V, mask=None):
"""
缩放点积注意力
Q, K, V: (batch, num_heads, seq_len, d_k)
mask: (batch, 1, 1, seq_len) 或 (1, 1, seq_len, seq_len)
"""
# Step 1: 计算注意力分数
scores = torch.matmul(Q, K.transpose(-2, -1)) / self.scale
# scores: (batch, num_heads, seq_len_q, seq_len_k)
# Step 2: 应用掩码(如有)
if mask is not None:
scores = scores.masked_fill(mask == 0, float('-inf'))
# Step 3: Softmax归一化
attn_weights = F.softmax(scores, dim=-1)
attn_weights = self.dropout(attn_weights)
# Step 4: 加权求和
output = torch.matmul(attn_weights, V)
# output: (batch, num_heads, seq_len_q, d_k)
return output, attn_weights
def forward(self, query, key, value, mask=None):
"""
前向传播
query, key, value: (batch, seq_len, d_model)
mask: 可选掩码
Returns: (batch, seq_len, d_model), attention_weights
"""
batch_size = query.size(0)
# 1. 线性投影
Q = self.W_q(query) # (batch, seq_len, d_model)
K = self.W_k(key)
V = self.W_v(value)
# 2. 拆分为多头
Q = self.split_heads(Q, batch_size) # (batch, num_heads, seq_len, d_k)
K = self.split_heads(K, batch_size)
V = self.split_heads(V, batch_size)
# 3. 缩放点积注意力
attn_output, attn_weights = self.scaled_dot_product_attention(Q, K, V, mask)
# 4. 合并多头
attn_output = attn_output.transpose(1, 2).contiguous()
attn_output = attn_output.view(batch_size, -1, self.d_model)
# 5. 输出投影
output = self.W_o(attn_output)
return output, attn_weights
# ==================== 测试 ====================
def test_multi_head_attention():
d_model = 512
num_heads = 8
seq_len = 20
batch_size = 4
mha = MultiHeadAttention(d_model=d_model, num_heads=num_heads)
# 自注意力测试
x = torch.randn(batch_size, seq_len, d_model)
output, weights = mha(x, x, x)
print(f"Input shape: {x.shape}")
print(f"Output shape: {output.shape}")
print(f"Attention weights shape: {weights.shape}")
assert output.shape == (batch_size, seq_len, d_model)
assert weights.shape == (batch_size, num_heads, seq_len, seq_len)
# 验证注意力权重行和为1
row_sums = weights.sum(dim=-1)
assert torch.allclose(row_sums, torch.ones_like(row_sums), atol=1e-6)
print("All tests passed!")
# 因果掩码测试
causal_mask = torch.tril(torch.ones(seq_len, seq_len)).unsqueeze(0).unsqueeze(0)
output_causal, weights_causal = mha(x, x, x, mask=causal_mask)
# 验证上三角的注意力权重为0
upper_attn = weights_causal[:, :, 0, 1:] # 第0个位置不应关注后面的位置
assert torch.allclose(upper_attn, torch.zeros_like(upper_attn), atol=1e-6)
print("Causal mask test passed!")
# test_multi_head_attention()
12. 复杂度分析与优化¶
12.1 标准注意力的复杂度¶
对于长度为 \(n\) 的序列,维度为 \(d\):
- 时间复杂度:\(O(n^2 \cdot d)\) — 主要来自 \(\mathbf{Q}\mathbf{K}^T\) 的计算
- 空间复杂度:\(O(n^2 + n \cdot d)\) — 需要存储 \(n \times n\) 的注意力矩阵
当 \(n\) 很大时(如处理长文档、高分辨率图像),\(n^2\) 成为严重瓶颈。
12.2 优化方向¶
稀疏注意力(Sparse Attention)¶
不计算完整的 \(n \times n\) 注意力矩阵,只计算其中一部分:
- 固定模式:滑动窗口 + 全局token(Longformer, BigBird)
- 学习模式:让模型学习关注哪些位置(Reformer用LSH近似)
复杂度降至 \(O(n \cdot \sqrt{n})\) 或 \(O(n \cdot w)\)(\(w\) 为窗口大小)。
线性注意力(Linear Attention)¶
利用核技巧将注意力重写为线性形式:
先计算 \(\phi(\mathbf{K})^T \mathbf{V} \in \mathbb{R}^{d \times d}\),再与 \(\phi(\mathbf{Q})\) 相乘,复杂度 \(O(n \cdot d^2)\)。
代表方法:Linear Transformer, Performer (Random Feature Attention)。
Flash Attention¶
不改变数学公式,而是利用GPU内存层次结构优化注意力计算的IO效率:
- 通过分块(tiling)将计算放到GPU SRAM中
- 避免将完整的 \(n \times n\) 注意力矩阵写回HBM
- 训练速度提升2-4倍,内存使用降至 \(O(n)\)
Flash Attention已成为现代大模型训练的标配(PyTorch 2.0+内置 torch.nn.functional.scaled_dot_product_attention 自动使用Flash Attention)。
状态空间模型(SSM)¶
Mamba等模型用结构化的状态空间方程替代注意力:
训练时可并行化(通过并行扫描),推理时为 \(O(1)\) 常量时间(类似RNN),是后Transformer时代的重要方向之一。
12.3 复杂度对比¶
| 方法 | 时间复杂度 | 空间复杂度 | 特点 |
|---|---|---|---|
| 标准注意力 | \(O(n^2 d)\) | \(O(n^2)\) | 精确,但不可扩展 |
| 稀疏注意力 | \(O(n \cdot w \cdot d)\) | \(O(n \cdot w)\) | 窗口大小 \(w\) 限制 |
| 线性注意力 | \(O(n d^2)\) | \(O(nd)\) | 近似,性能有损 |
| Flash Attention | \(O(n^2 d)\) | \(O(n)\) | 精确,IO优化 |
| SSM(Mamba) | \(O(nd)\) | \(O(nd)\) | 线性,新范式 |
13. 练习与自我检查¶
✏️ 练习题¶
-
手动计算:给定3个二维向量 \(\mathbf{x}_1=[1,0], \mathbf{x}_2=[0,1], \mathbf{x}_3=[1,1]\) 和 \(\mathbf{W}^Q=\mathbf{W}^K=\mathbf{W}^V=\mathbf{I}\)(单位矩阵),手动计算自注意力输出。
-
实现完整Transformer:基于本章提供的Multi-Head Attention,补全Transformer编码器和解码器的完整实现。
-
位置编码可视化:实现正弦位置编码,可视化不同位置和不同维度的编码值(热力图),观察周期性模式。
-
因果掩码验证:实现一个decoder-only Transformer,验证因果掩码确实阻止了信息泄露——打乱位置 \(i\) 之后的token不应影响位置 \(i\) 的输出。
-
注意力可视化:训练一个小型Transformer进行机器翻译,可视化不同头的注意力矩阵,分析各头学到了什么模式。
-
效率对比:实现标准注意力和Flash Attention(使用PyTorch 2.0的SDPA),在不同序列长度下对比速度和内存使用。
-
ViT实现:用PyTorch实现一个简化版ViT,在CIFAR-10上训练,对比与ResNet的效果。
面试要点¶
Q1: 解释Transformer中自注意力的计算过程? A: 输入经Q/K/V线性投影,计算Q和K的缩放点积得到注意力分数,经softmax归一化后加权求和V。公式:\(\text{softmax}(\frac{QK^T}{\sqrt{d_k}})V\)。Multi-Head将d_model拆分为多个头,分别计算后拼接投影。
Q2: 为什么要除以 \(\sqrt{d_k}\)? A: Q和K的点积期望为0、方差为\(d_k\)(假设各分量独立标准正态)。不缩放时,\(d_k\)大会导致softmax饱和(梯度极小)。除以\(\sqrt{d_k}\)将方差归一到1。
Q3: Pre-Norm和Post-Norm的区别? A: Post-Norm在残差之后归一化(Layer→Residual→Norm),训练不稳定需要warmup。Pre-Norm先归一化再进子层(Norm→Layer→Residual),训练更稳定,是现代大模型的标准选择。
Q4: GPT和BERT在架构上有什么区别? A: BERT用Transformer编码器(双向注意力+MLM预训练),适合理解任务。GPT用Transformer解码器(因果注意力+自回归LM预训练),适合生成任务。GPT架构已成为大模型主流。
Q5: Transformer处理长序列有什么问题,如何优化? A: 标准注意力\(O(n^2)\)复杂度,长序列计算和内存开销巨大。优化方向:稀疏注意力(Longformer)、Flash Attention(IO优化)、线性注意力(核近似)、SSM(Mamba,线性复杂度)。
自我检查清单¶
- 能完整写出缩放点积注意力公式和Multi-Head Attention公式
- 理解Q/K/V的直觉含义和数学作用
- 理解为什么要缩放(\(\sqrt{d_k}\))
- 能解释正弦位置编码的设计思想,了解RoPE的优势
- 理解编码器和解码器的结构差异(掩码、交叉注意力)
- 能从零实现Multi-Head Attention
- 理解Pre-Norm vs Post-Norm的实际影响
- 能说清BERT和GPT的架构选择和适用场景
- 了解至少3种注意力优化方法
- 理解ViT如何将图像转化为token序列
下一章: ../02-卷积神经网络/01-卷积神经网络基础 — 或继续进阶章节