02 - 神经网络基础¶
重要性: ⭐⭐⭐⭐⭐ 实用度: ⭐⭐⭐⭐⭐ 学习时间: 5小时 必须掌握: 是
为什么学这一章?¶
神经网络是深度学习的基石。理解神经网络的基础原理能帮助你: - 理解深度学习模型的基本构建块 - 掌握前向传播的计算过程 - 理解神经网络的表达能力理论 - 能够从零实现简单的神经网络
学完这一章,你将能够: - ✅ 解释感知机的工作原理 - ✅ 理解多层感知机(MLP)的结构 - ✅ 手动计算简单网络的前向传播 - ✅ 理解万能逼近定理及其意义 - ✅ 理解深度vs宽度的理论分析 - ✅ 用NumPy实现一个MLP
📖 感知机:神经网络的起点¶
感知机模型¶
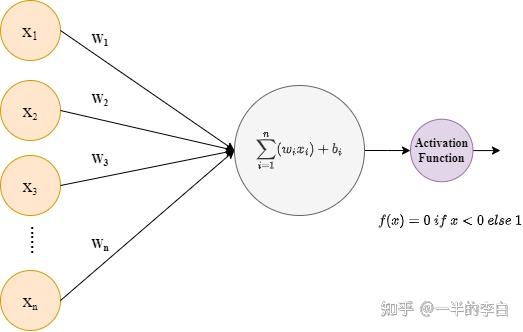
图注:人工神经元模型
感知机(Perceptron)是最简单的神经网络,由Rosenblatt于1958年提出。
┌─────────────────────────────────────────────────────────────────────┐
│ 感知机结构 │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 感知机(单输出) │
│ │
│ 输入 加权求和 激活 │
│ ┌─────┐ ┌─────────┐ ┌───────┐ │
│ │ x₁ │───w₁────────→ │ │ │ │ │
│ │ x₂ │───w₂────────→ │ Σwᵢxᵢ │───→f()──→│ 输出 y │ │
│ │ x₃ │───w₃────────→ │ + b │ │ │ │
│ │ ... │ │ │ └───────┘ │
│ │ xₙ │───wₙ────────→ │ │ │
│ └─────┘ └─────────┘ │
│ ↑ ↑ │
│ 输入特征 偏置b │
│ │
│ 数学公式: │
│ z = w₁x₁ + w₂x₂ + ... + wₙxₙ + b │
│ y = f(z) │
│ │
│ 其中: │
│ • xᵢ:输入特征(如像素值) │
│ • wᵢ:权重(学习的参数) │
│ • b:偏置(学习的参数) │
│ • f:激活函数(如阶跃函数) │
│ │
└─────────────────────────────────────────────────────────────────────┘
感知机的决策边界¶
┌─────────────────────────────────────────────────────────────────────┐
│ 感知机的几何解释 │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 二分类问题(以二维为例): │
│ │
│ x₂ │
│ ↑ │
│ │ × × │
│ │ × × × 决策边界: w₁x₁ + w₂x₂ + b = 0 │
│ │ × × × ╱ │
│ │ × × × ╱ ←──── 超平面(直线) │
│ │ × × ╱ ○ │
│ │ × × ╱ ○ ○ │
│ │ × ╱ ○ ○ ○ │
│ │ ╱ ○ ○ ○ │
│ └──────────────────────→ x₁ │
│ │
│ • ×:类别A(如:猫) │
│ • ○:类别B(如:狗) │
│ • 直线:决策边界,将两类分开 │
│ │
│ 关键洞察: │
│ 感知机学习的是输入空间中的一个超平面,将不同类别分开 │
│ │
└─────────────────────────────────────────────────────────────────────┘
感知机的局限:XOR问题¶
┌─────────────────────────────────────────────────────────────────────┐
│ 感知机的局限:无法解决XOR问题 │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ XOR问题(异或): │
│ │
│ x₂ │
│ ↑ │
│ │ 0 1 │
│ │ ↑ │
│ │ 0 │ 无法用一条直线分开! │
│ │ │ │
│ │ ──────┼────── │
│ │ │ │
│ │ 1 │ 0 │
│ │ ↓ │
│ └──────────────────→ x₁ │
│ │
│ XOR真值表: │
│ ┌─────┬─────┬───────┐ │
│ │ x₁ │ x₂ │ x₁⊕x₂ │ │
│ ├─────┼─────┼───────┤ │
│ │ 0 │ 0 │ 0 │ │
│ │ 0 │ 1 │ 1 │ │
│ │ 1 │ 0 │ 1 │ │
│ │ 1 │ 1 │ 0 │ │
│ └─────┴─────┴───────┘ │
│ │
│ 关键洞察: │
│ 单层感知机只能解决线性可分问题 │
│ XOR问题不是线性可分的,需要多层网络 │
│ │
└─────────────────────────────────────────────────────────────────────┘
🏗️ 多层感知机(MLP)¶
从单层到多层¶
┌─────────────────────────────────────────────────────────────────────┐
│ 多层感知机(MLP)结构 │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 输入层 隐藏层1 隐藏层2 输出层 │
│ ┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐ │
│ │ x₁ │────→│ h₁ │ ┌───→│ h₁' │ ┌───→│ y₁ │ │
│ │ x₂ │────→│ h₂ │───┤ │ h₂' │───┤ │ y₂ │ │
│ │ x₃ │────→│ h₃ │ │ │ h₃' │ │ │ ... │ │
│ │ ... │ │ ... │ │ │ ... │ │ │ yₖ │ │
│ │ xₙ │────→│ hₘ │───┘ └─────┘ └───→└─────┘ │
│ └─────┘ └─────┘ │
│ │
│ 层间连接: │
│ • 输入层 → 隐藏层1:全连接(每个输入连接到每个隐藏单元) │
│ • 隐藏层1 → 隐藏层2:全连接 │
│ • 隐藏层2 → 输出层:全连接 │
│ │
│ 为什么能解决XOR? │
│ 多层网络可以学习非线性决策边界! │
│ │
│ x₂ │
│ ↑ │
│ │ 0 1 │
│ │ ╲ ╱ │
│ │ ╲ ╱ 两条直线组合成非线性边界 │
│ │ × │
│ │ ╱ ╲ │
│ │ 1 ╲ 0 │
│ └──────────────────→ x₁ │
│ │
└─────────────────────────────────────────────────────────────────────┘
前向传播计算¶
神经网络前向传播¶

图注:神经网络前向传播
┌─────────────────────────────────────────────────────────────────────┐
│ 前向传播计算过程 │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 示例:2-3-1网络(2输入,3隐藏单元,1输出) │
│ │
│ 输入: x = [x₁, x₂] = [0.5, 0.3] │
│ │
│ 第1层(输入层 → 隐藏层): │
│ ┌─────────────────────────────────────────────────────────────┐ │
│ │ 权重 W¹ = [[w₁₁, w₁₂, w₁₃], 偏置 b¹ = [b₁, b₂, b₃] │ │
│ │ [w₂₁, w₂₂, w₂₃]] │ │
│ │ │ │
│ │ z₁ = x₁·w₁₁ + x₂·w₂₁ + b₁ │ │
│ │ z₂ = x₁·w₁₂ + x₂·w₂₂ + b₂ │ │
│ │ z₃ = x₁·w₁₃ + x₂·w₂₃ + b₃ │ │
│ │ │ │
│ │ h₁ = f(z₁), h₂ = f(z₂), h₃ = f(z₃) ← 激活函数 │ │
│ └─────────────────────────────────────────────────────────────┘ │
│ │
│ 第2层(隐藏层 → 输出层): │
│ ┌─────────────────────────────────────────────────────────────┐ │
│ │ 权重 W² = [w₁, w₂, w₃]ᵀ 偏置 b² = b │ │
│ │ │ │
│ │ z = h₁·w₁ + h₂·w₂ + h₃·w₃ + b │ │
│ │ │ │
│ │ y = f(z) ← 输出激活函数 │ │
│ └─────────────────────────────────────────────────────────────┘ │
│ │
│ 矩阵形式(更简洁): │
│ h = f(x · W¹ + b¹) │
│ y = f(h · W² + b²) │
│ │
└─────────────────────────────────────────────────────────────────────┘
手动计算示例¶
┌─────────────────────────────────────────────────────────────────────┐
│ 手动计算示例 │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 网络结构:2-2-1(2输入,2隐藏单元,1输出) │
│ │
│ 给定: │
│ 输入: x = [1.0, 0.5] │
│ │
│ 权重(已学习得到): │
│ W¹ = [[0.1, 0.2], b¹ = [0.1, 0.2] │
│ [0.3, 0.4]] │
│ │
│ W² = [0.5, 0.6]ᵀ b² = 0.3 │
│ │
│ 激活函数:Sigmoid: f(z) = 1 / (1 + e^(-z)) │
│ │
│ ───────────────────────────────────────────────────────────────── │
│ │
│ Step 1: 计算隐藏层输入 │
│ z₁ = 1.0×0.1 + 0.5×0.3 + 0.1 = 0.35 │
│ z₂ = 1.0×0.2 + 0.5×0.4 + 0.2 = 0.60 │
│ │
│ Step 2: 应用激活函数 │
│ h₁ = sigmoid(0.35) = 1/(1+e^(-0.35)) ≈ 0.587 │
│ h₂ = sigmoid(0.60) = 1/(1+e^(-0.60)) ≈ 0.646 │
│ │
│ Step 3: 计算输出层输入 │
│ z = 0.587×0.5 + 0.646×0.6 + 0.3 ≈ 0.981 │
│ │
│ Step 4: 应用输出激活函数 │
│ y = sigmoid(0.981) ≈ 0.727 │
│ │
│ ───────────────────────────────────────────────────────────────── │
│ │
│ 最终结果:y ≈ 0.727 │
│ │
│ 如果这是二分类问题(输出0或1): │
│ y > 0.5 → 预测为类别1 │
│ y ≤ 0.5 → 预测为类别0 │
│ │
└─────────────────────────────────────────────────────────────────────┘
🧮 核心理论:万能逼近定理¶
什么是万能逼近定理?¶
万能逼近定理(Universal Approximation Theorem)是神经网络理论的基石,它证明了神经网络的强大表达能力。
┌─────────────────────────────────────────────────────────────────────┐
│ 万能逼近定理 │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 定理陈述(Cybenko, 1989; Hornik et al., 1989): │
│ │
│ 具有至少一个隐藏层的前馈神经网络,只要隐藏层有足够多的神经元, │
│ 并且使用非线性激活函数(如Sigmoid、ReLU),就可以以任意精度 │
│ 逼近任意连续函数。 │
│ │
│ 数学表述: │
│ │
│ 对于任意连续函数 f: [0,1]ⁿ → ℝ 和任意 ε > 0, │
│ 存在一个具有单隐藏层的神经网络 g,使得: │
│ │
│ |f(x) - g(x)| < ε 对所有 x ∈ [0,1]ⁿ 成立 │
│ │
│ ───────────────────────────────────────────────────────────────── │
│ │
│ 直观理解: │
│ │
│ 目标函数 f(x) = sin(2πx) 神经网络逼近 g(x) │
│ │╲ ╱│ │╲ ╱│ │
│ │ ╲ ╱ │ │ ╲ ╱ │ │
│ │ ╲╱ │ │ ╲╱ │ │
│ └──────┘ └──────┘ │
│ │
│ 只要隐藏层神经元足够多,神经网络可以逼近任意复杂的函数! │
│ │
└─────────────────────────────────────────────────────────────────────┘
万能逼近定理的直观解释¶
┌─────────────────────────────────────────────────────────────────────┐
│ 为什么神经网络能逼近任意函数? │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 核心思想:用多个" bump函数 "组合逼近任意函数 │
│ │
│ 单个神经元(Sigmoid): │
│ │
│ 1 │ ╭──────╮ │
│ │ ╱ ╲ │
│ 0 │──────╱ ╲──────── │
│ └────────────────────────→ x │
│ │
│ 两个神经元的组合: │
│ │
│ 1 │ ╭──╮ ╭──╮ │
│ │ ╱ ╲ ╱ ╲ │
│ 0 │──╱ ╲──╱ ╲──── │
│ └────────────────────────→ x │
│ │
│ 多个神经元的组合可以逼近任意形状: │
│ │
│ 1 │ ╭─╮ ╭──╮ ╭╮ ╭──╮ │
│ │ ╱ ╲╱ ╲ ╱ ╲ ╱ ╲ │
│ 0 │──╱ ╳ ╳ ╲─── │
│ └────────────────────────→ x │
│ │
│ 关键洞察: │
│ • 每个神经元学习一个局部的"特征" │
│ • 足够多的神经元可以组合出任意复杂的函数 │
│ • 这就是深度学习的表达能力来源! │
│ │
└─────────────────────────────────────────────────────────────────────┘
万能逼近定理的局限性¶
┌─────────────────────────────────────────────────────────────────────┐
│ 万能逼近定理的局限性 │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 定理只保证存在性,不保证: │
│ │
│ 1. 网络能找到最优权重 │
│ ┌─────────────────────────────────────────┐ │
│ │ 训练可能陷入局部最优 │ │
│ │ 梯度下降不保证找到全局最优 │ │
│ └─────────────────────────────────────────┘ │
│ │
│ 2. 网络能在合理时间内收敛 │
│ ┌─────────────────────────────────────────┐ │
│ │ 可能需要指数级的训练时间 │ │
│ │ 实际应用中需要优化算法和技巧 │ │
│ └─────────────────────────────────────────┘ │
│ │
│ 3. 网络能泛化到新数据 │
│ ┌─────────────────────────────────────────┐ │
│ │ 可能过拟合训练数据 │ │
│ │ 需要正则化、早停等技术 │ │
│ └─────────────────────────────────────────┘ │
│ │
│ 4. 网络规模是可行的 │
│ ┌─────────────────────────────────────────┐ │
│ │ 可能需要指数级数量的神经元 │ │
│ │ 深层网络可以用更少参数表示复杂函数 │ │
│ └─────────────────────────────────────────┘ │
│ │
│ 这就是为什么需要: │
│ • 深层网络(深度比宽度更重要) │
│ • 更好的优化算法(Adam、学习率调度) │
│ • 正则化技术(Dropout、权重衰减) │
│ │
└─────────────────────────────────────────────────────────────────────┘
📊 深度 vs 宽度:网络架构的理论分析¶
深度与宽度的权衡¶
┌─────────────────────────────────────────────────────────────────────┐
│ 深度 vs 宽度:网络架构设计 │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 浅而宽的网络 深而窄的网络 │
│ │
│ ┌─────────────────┐ ┌───┐ │
│ │ 输入 │ │输入│ │
│ └────────┬────────┘ └───┘ │
│ ↓ ↓ │
│ ┌─────────────────┐ ┌───┐ │
│ │ 隐藏层 │ │H1 │ │
│ │ (1000神经元) │ └───┘ │
│ └────────┬────────┘ ↓ │
│ ↓ ┌───┐ │
│ ┌─────────────────┐ │H2 │ │
│ │ 输出 │ └───┘ │
│ └─────────────────┘ ↓ │
│ ┌───┐ │
│ │H3 │ │
│ └───┘ │
│ ↓ │
│ ┌───┐ │
│ │H4 │ │
│ └───┘ │
│ ↓ │
│ ┌───┐ │
│ │H5 │ │
│ └───┘ │
│ ↓ │
│ ┌───┐ │
│ │输出│ │
│ └───┘ │
│ │
│ 参数数量相似,但表达能力不同! │
│ │
└─────────────────────────────────────────────────────────────────────┘
为什么深度更重要?¶
┌─────────────────────────────────────────────────────────────────────┐
│ 深度的指数级优势 │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 理论结果(Eldan & Shamir, 2016; Telgarsky, 2016): │
│ │
│ 存在一类函数,浅层网络需要指数级数量的神经元才能表示, │
│ 而深层网络只需要多项式数量的神经元。 │
│ │
│ 具体例子: │
│ │
│ 函数:f(x) = x²ⁿ(n次平方) │
│ │
│ 浅层网络(2层): │
│ • 需要 O(2ⁿ) 个神经元 │
│ • 指数级增长,不可行 │
│ │
│ 深层网络(O(n)层): │
│ • 只需要 O(n) 个神经元 │
│ • 线性增长,完全可行 │
│ │
│ ───────────────────────────────────────────────────────────────── │
│ │
│ 直观解释: │
│ │
│ 深层网络的每一层都在进行"特征组合": │
│ │
│ 第1层:学习边缘(简单特征) │
│ ↓ │
│ 第2层:学习纹理(组合边缘) │
│ ↓ │
│ 第3层:学习部件(组合纹理) │
│ ↓ │
│ 第4层:学习对象(组合部件) │
│ │
│ 每一层都在前一层的基础上构建更复杂的特征! │
│ 这种层次化结构符合现实世界的组织方式。 │
│ │
└─────────────────────────────────────────────────────────────────────┘
深度与宽度的实践指导¶
┌─────────────────────────────────────────────────────────────────────┐
│ 网络架构设计实践指南 │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 一般原则: │
│ │
│ 1. 优先增加深度 │
│ ┌─────────────────────────────────────────┐ │
│ │ 从3-5层开始,逐步增加深度 │ │
│ │ ResNet可以训练100+层的网络 │ │
│ │ 深度带来的收益通常大于宽度 │ │
│ └─────────────────────────────────────────┘ │
│ │
│ 2. 合理设置宽度 │
│ ┌─────────────────────────────────────────┐ │
│ │ 隐藏层神经元数:64, 128, 256, 512... │ │
│ │ 通常每层宽度相同或递减 │ │
│ │ 输入层→隐藏层→输出层:宽→窄 │ │
│ └─────────────────────────────────────────┘ │
│ │
│ 3. 避免过宽或过深 │
│ ┌─────────────────────────────────────────┐ │
│ │ 太宽:容易过拟合,计算效率低 │ │
│ │ 太深:梯度消失/爆炸,训练困难 │ │
│ │ 需要残差连接、批归一化等技术 │ │
│ └─────────────────────────────────────────┘ │
│ │
│ 典型架构: │
│ │
│ 简单任务(MNIST): │
│ 输入(784) → 隐藏层1(256) → 隐藏层2(128) → 输出(10) │
│ │
│ 中等复杂度(CIFAR-10): │
│ 使用CNN:Conv → Conv → Pool → Conv → Conv → Pool → FC → FC → Output │
│ │
│ 复杂任务(ImageNet): │
│ ResNet-50:50层,包含残差连接 │
│ │
└─────────────────────────────────────────────────────────────────────┘
🔧 激活函数:引入非线性¶
为什么需要激活函数?¶
┌─────────────────────────────────────────────────────────────────────┐
│ 为什么需要激活函数? │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 假设没有激活函数(线性激活): │
│ │
│ 第1层:h = x · W¹ + b¹ │
│ 第2层:y = h · W² + b² │
│ │
│ 合并:y = (x · W¹ + b¹) · W² + b² │
│ y = x · (W¹·W²) + (b¹·W² + b²) │
│ y = x · W' + b' │
│ │
│ 结论:多层线性网络等价于单层线性网络! │
│ 无法学习非线性模式! │
│ │
│ ┌─────────────────────────────────────────────────────────────┐ │
│ │ 没有激活函数 有激活函数 │ │
│ │ │ │
│ │ 输入 ──→ [线性] ──→ [线性] ──→ 输出 输入 ──→ [线性+非线性] ──→ │ │
│ │ ↓ ↓ │ │
│ │ 等价于单层网络 可以学习复杂模式 │ │
│ │ 只能解决线性问题 可以解决非线性问题 │ │
│ └─────────────────────────────────────────────────────────────┘ │
│ │
│ 关键洞察: │
│ 激活函数引入非线性,使网络能学习复杂模式 │
│ │
└─────────────────────────────────────────────────────────────────────┘
常用激活函数¶
┌─────────────────────────────────────────────────────────────────────┐
│ 常用激活函数对比 │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 1. Sigmoid │
│ ┌─────────────────────────────────────────────────────────────┐ │
│ │ f(z) = 1 / (1 + e^(-z)) │ │
│ │ │ │
│ │ 1 │ ╭──────╮ │ │
│ │ │ ╱ ╲ │ │
│ │ 0.5 │──────╱ ╲──────── │ │
│ │ │ ╱ ╲ │ │
│ │ 0 │────╱ ╲────── │ │
│ │ └────────────────────────→ z │ │
│ │ -4 -2 0 2 4 │ │
│ │ │ │
│ │ 导数:f'(z) = f(z) · (1 - f(z)) │ │
│ │ │ │
│ │ 优点:输出范围(0,1),可解释为概率 │ │
│ │ 缺点:梯度消失(两端饱和),输出非0中心化 │ │
│ │ 用途:二分类输出层 │ │
│ └─────────────────────────────────────────────────────────────┘ │
│ │
│ 2. Tanh(双曲正切) │
│ ┌─────────────────────────────────────────────────────────────┐ │
│ │ f(z) = (e^z - e^(-z)) / (e^z + e^(-z)) │ │
│ │ │ │
│ │ 1 │ ╭──────╮ │ │
│ │ │ ╱ ╲ │ │
│ │ 0 │──────╱ ╲──────── │ │
│ │ │ ╱ ╲ │ │
│ │ -1 │────╱ ╲────── │ │
│ │ └────────────────────────→ z │ │
│ │ -4 -2 0 2 4 │ │
│ │ │ │
│ │ 导数:f'(z) = 1 - f(z)² │ │
│ │ │ │
│ │ 优点:输出范围(-1,1),0中心化 │ │
│ │ 缺点:仍有梯度消失问题 │ │
│ │ 用途:隐藏层(早期使用) │ │
│ └─────────────────────────────────────────────────────────────┘ │
│ │
│ 3. ReLU(Rectified Linear Unit)⭐ 最常用 │
│ ┌─────────────────────────────────────────────────────────────┐ │
│ │ f(z) = max(0, z) │ │
│ │ │ │
│ │ │ ╱ │ │
│ │ │ ╱ │ │
│ │ │ ╱ │ │
│ │ 0 │─────╱──────────────── │ │
│ │ │ ╱ │ │
│ │ └────────────────────────→ z │ │
│ │ -4 -2 0 2 4 │ │
│ │ │ │
│ │ 导数:f'(z) = 1 if z > 0, else 0 │ │
│ │ │ │
│ │ 优点:计算简单,缓解梯度消失,收敛快 │ │
│ │ 缺点:Dead ReLU(负数区域梯度为0) │ │
│ │ 用途:隐藏层默认选择 │ │
│ └─────────────────────────────────────────────────────────────┘ │
│ │
│ 4. Softmax(多分类输出) │
│ ┌─────────────────────────────────────────────────────────────┐ │
│ │ f(zᵢ) = e^(zᵢ) / Σⱼe^(zⱼ) │ │
│ │ │ │
│ │ 将任意实数向量转换为概率分布(和为1) │ │
│ │ │ │
│ │ 输入: [2.0, 1.0, 0.1] │ │
│ │ 输出: [0.7, 0.2, 0.1] ← 概率分布 │ │
│ │ │ │
│ │ 用途:多分类问题的输出层 │ │
│ └─────────────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────────┘
🧪 动手实验:NumPy实现MLP¶
让我们从零开始,用NumPy实现一个多层感知机。
完整代码¶
import numpy as np
class MLP:
"""
多层感知机(MLP)的NumPy实现
架构:输入层 → 隐藏层 → 输出层
"""
def __init__(self, input_size, hidden_size, output_size): # __init__构造方法,创建对象时自动调用
"""
初始化网络参数
Args:
input_size: 输入特征维度
hidden_size: 隐藏层神经元数量
output_size: 输出类别数量
"""
# 初始化权重(使用He初始化,适用于ReLU激活函数)
self.W1 = np.random.randn(input_size, hidden_size) * np.sqrt(2.0 / input_size)
self.b1 = np.zeros(hidden_size)
self.W2 = np.random.randn(hidden_size, output_size) * np.sqrt(2.0 / hidden_size)
self.b2 = np.zeros(output_size)
print(f"网络结构: {input_size}-{hidden_size}-{output_size}")
print(f"参数数量: {input_size*hidden_size + hidden_size + hidden_size*output_size + output_size}")
def relu(self, x):
"""ReLU激活函数"""
return np.maximum(0, x)
def softmax(self, x):
"""Softmax激活函数"""
exp_x = np.exp(x - np.max(x, axis=1, keepdims=True))
return exp_x / np.sum(exp_x, axis=1, keepdims=True)
def forward(self, X):
"""
前向传播
Args:
X: 输入数据,形状 (batch_size, input_size)
Returns:
输出概率,形状 (batch_size, output_size)
"""
# 第1层:输入 → 隐藏层
self.z1 = np.dot(X, self.W1) + self.b1 # 线性变换
self.h = self.relu(self.z1) # ReLU激活
# 第2层:隐藏层 → 输出层
self.z2 = np.dot(self.h, self.W2) + self.b2 # 线性变换
self.y_pred = self.softmax(self.z2) # Softmax激活
return self.y_pred
def compute_loss(self, y_pred, y_true):
"""
计算交叉熵损失
Args:
y_pred: 预测概率 (batch_size, output_size)
y_true: 真实标签 (batch_size,)
Returns:
平均损失
"""
batch_size = y_pred.shape[0]
# 获取正确类别的概率
correct_logprobs = -np.log(y_pred[range(batch_size), y_true] + 1e-8)
return np.sum(correct_logprobs) / batch_size
def predict(self, X):
"""预测类别"""
y_pred = self.forward(X)
return np.argmax(y_pred, axis=1)
def accuracy(self, X, y):
"""计算准确率"""
predictions = self.predict(X)
return np.mean(predictions == y)
# ==================== 测试代码 ====================
if __name__ == "__main__":
# 生成模拟数据(3类分类问题)
np.random.seed(42)
# 训练数据:100个样本,4维特征,3个类别
X_train = np.random.randn(100, 4)
y_train = np.random.randint(0, 3, 100)
# 创建网络
model = MLP(input_size=4, hidden_size=10, output_size=3)
# 测试前向传播
print("\n测试前向传播...")
output = model.forward(X_train[:5]) # 切片操作取子序列
print(f"输入形状: {X_train[:5].shape}")
print(f"输出形状: {output.shape}")
print(f"输出概率和: {output.sum(axis=1)}") # 应该接近1
# 测试预测
print("\n测试预测...")
predictions = model.predict(X_train[:10])
print(f"预测结果: {predictions}")
print(f"真实标签: {y_train[:10]}")
print(f"准确率: {model.accuracy(X_train[:10], y_train[:10]):.2%}")
# 测试损失计算
print("\n测试损失计算...")
loss = model.compute_loss(output, y_train[:5])
print(f"损失值: {loss:.4f}")
print("\n✅ 所有测试通过!")
运行结果¶
网络结构: 4-10-3
参数数量: 73
测试前向传播...
输入形状: (5, 4)
输出形状: (5, 3)
输出概率和: [1. 1. 1. 1. 1.]
测试预测...
预测结果: [1 1 0 0 1 0 1 1 1 2]
真实标签: [0 2 1 0 1 2 2 0 0 2]
准确率: 20.00%
测试损失计算...
损失值: 1.0986
✅ 所有测试通过!
注意:准确率较低是因为权重是随机初始化的,还没有训练。下一章我们将学习如何训练网络!
💡 核心要点总结¶
感知机¶
- 最简单的神经网络单元
- 学习线性决策边界
- 无法解决非线性可分问题(如XOR)
多层感知机(MLP)¶
- 通过多层结构学习非线性映射
- 每层执行:线性变换 + 非线性激活
- 可以逼近任意连续函数(万能逼近定理)
万能逼近定理¶
- 单隐藏层网络可以逼近任意连续函数
- 只保证存在性,不保证能找到或泛化
- 深层网络可以用更少参数表示复杂函数
深度 vs 宽度¶
- 深度比宽度更重要
- 深层网络具有指数级表达能力优势
- 实际设计中优先增加深度
前向传播¶
激活函数¶
| 函数 | 公式 | 优点 | 缺点 | 隐藏层推荐度 | 典型用途 |
|---|---|---|---|---|---|
| Sigmoid | $\(\sigma(z) = \frac{1}{1+e^{-z}}\)$ | 输出概率 | 梯度消失 | ⭐ (不推荐) | 二分类输出层 |
| Tanh | $\(\tanh(z) = \frac{e^z-e^{-z}}{e^z+e^{-z}}\)$ | 0中心化 | 梯度消失 | ⭐⭐ (较少用) | RNN隐藏层 |
| ReLU | $\(\text{ReLU}(z) = \max(0,z)\)$ | 简单、快速 | Dead ReLU | ⭐⭐⭐⭐⭐ (默认) | CNN/MLP隐藏层 |
| LeakyReLU | $\(\text{LeakyReLU}(z) = \max(\alpha z,z)\)$ | 避免Dead ReLU | 需调α | ⭐⭐⭐⭐ | GAN、深层网络 |
| Softmax | $\(\text{Softmax}(z_i) = \frac{e^{z_i}}{\sum_j e^{z_j}}\)$ | 概率分布 | - | - (仅输出层) | 多分类输出层 |
❓ 常见问题¶
Q1:为什么需要偏置(bias)?
A:偏置允许决策边界不经过原点。没有偏置,网络只能学习经过原点的线性变换,限制了表达能力。
Q2:权重为什么要随机初始化?
A:如果所有权重初始化为相同值,所有神经元将学习相同的特征,网络失去意义。随机初始化打破对称性,让每个神经元学习不同的特征。
Q3:隐藏层需要多少神经元?
A:没有固定规则,通常: - 从较少神经元开始(如64、128) - 根据任务复杂度调整 - 更多神经元 = 更强表达能力,但也更容易过拟合
Q4:需要多少层隐藏层?
A: - 简单问题:1-2层 - 复杂问题:3-5层或更多 - 现代深度网络:几十到几百层(ResNet、Transformer)
Q5:如何选择激活函数?
A: - 隐藏层:默认使用ReLU - 二分类输出:Sigmoid - 多分类输出:Softmax - 回归输出:线性(无激活)
Q6:万能逼近定理意味着什么?
A:它证明了神经网络具有强大的表达能力,理论上可以逼近任何函数。但这只是存在性定理,实际训练中还需要考虑优化、泛化等问题。
Q7:为什么深度比宽度更重要?
A:深层网络可以通过层次化组合特征,用指数级更少的参数表示复杂函数。这符合现实世界的层次化结构(如图像的边→纹理→部件→对象)。
Q8:什么是Batch Normalization?为什么有效?
A: - BN的作用:对每一层的输入进行归一化,使其均值为0,方差为1 - 为什么有效: 1. 缓解内部协变量偏移(Internal Covariate Shift) 2. 允许使用更大的学习率,加速收敛 3. 减少对初始化的敏感性 4. 有轻微的正则化效果 - 训练vs测试:训练时使用当前batch的统计量,测试时使用训练集的移动平均统计量
📝 自测问题¶
- 感知机为什么不能解决XOR问题?MLP如何解决?
- 写出2-3-2网络的前向传播公式。
- 为什么激活函数必须是非线性的?
- ReLU相比Sigmoid有什么优势?
- 什么是万能逼近定理?它有什么局限性?
- 为什么深度比宽度更重要?
- 用NumPy实现一个2-4-3的MLP前向传播。
📚 扩展阅读¶
- 《Perceptrons》 - Minsky & Papert(感知机局限性的经典著作)
- 《Neural Networks and Deep Learning》 - Michael Nielsen(第1-2章)
- Approximation by Superpositions of a Sigmoidal Function - Cybenko, 1989(万能逼近定理)
- The Power of Depth for Feedforward Neural Networks - Eldan & Shamir, 2016(深度vs宽度)
- CS231n Lecture 4 - Backpropagation and Neural Networks
🎯 下一步¶
继续学习 03-激活函数详解 和 04-损失函数与优化,然后学习反向传播算法,完成手写神经网络的训练。