01 - 深度学习概述¶
重要性: ⭐⭐⭐⭐⭐ 实用度: ⭐⭐⭐⭐⭐ 学习时间: 5小时 必须掌握: 是
为什么学这一章?¶
深度学习正在改变我们的世界。理解深度学习能帮助你: - 理解AI背后的核心原理 - 掌握现代计算机视觉和自然语言处理的基础 - 为学习大语言模型、扩散模型等前沿技术打下基础 - 培养解决复杂问题的能力
学完这一章,你将能够: - ✅ 解释什么是深度学习及其核心思想 - ✅ 了解深度学习的发展历史和关键里程碑 - ✅ 理解表示学习理论和深度网络的优势 - ✅ 掌握深度学习的优势和局限性 - ✅ 了解深度学习的主要应用领域 - ✅ 明确学习深度学习的正确心态
📖 什么是深度学习?¶
从生物神经元到人工神经网络¶
生物神经元与人工神经元对比¶
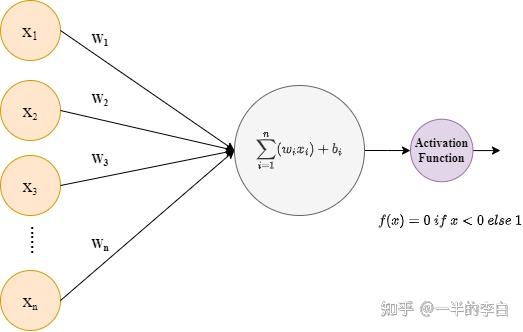
图注:感知机原始架构(1958年Rosenblatt提出)
┌─────────────────────────────────────────────────────────────────────┐
│ 从生物到人工:神经网络的灵感 │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 生物神经元 人工神经元(感知机) │
│ │
│ 树突 输入 │
│ ↓ ↓ │
│ ┌─────┐ 信号 ┌─────────────────────┐ │
│ ───→│ 细胞体 │────────→ │ 加权求和 → 激活函数 │──→ 输出 │
│ └──┬──┘ └─────────────────────┘ │
│ ↓ │
│ 轴突 │
│ │
│ 工作原理: │
│ 1. 接收多个输入信号(树突) │
│ 2. 整合信号,决定是否激活(细胞体) │
│ 3. 传递信号给其他神经元(轴突) │
│ │
│ 关键思想:简单的单元通过连接形成复杂系统 │
│ │
└─────────────────────────────────────────────────────────────────────┘
深度学习的定义¶
深度神经网络架构¶

图注:深度神经网络架构
深度学习是机器学习的一个分支,它使用多层神经网络来自动学习数据的层次化特征表示。
┌─────────────────────────────────────────────────────────────────────┐
│ 深度学习的核心要素 │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 深度学习 = 深度神经网络 + 大规模数据 + 强大算力 │
│ │
│ ┌───────────────────────────────────────────────────────────────┐ │
│ │ 深度神经网络 │ │
│ │ │ │
│ │ 输入层 隐藏层1 隐藏层2 隐藏层3 输出层 │ │
│ │ ┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐ │ │
│ │ │ │───→│ │───→│ │───→│ │───→│ │ │ │
│ │ │ 像素 │ │边缘 │ │纹理 │ │部件 │ │类别 │ │ │
│ │ │ 值 │ │检测 │ │识别 │ │检测 │ │预测 │ │ │
│ │ └─────┘ └─────┘ └─────┘ └─────┘ └─────┘ │ │
│ │ │ │
│ │ 特征层次:低级特征 → 中级特征 → 高级特征 → 决策 │ │
│ │ │ │
│ └───────────────────────────────────────────────────────────────┘ │
│ │
│ 关键特性: │
│ • 多层结构(通常3层以上) │
│ • 自动特征学习(无需人工设计) │
│ • 端到端训练(直接从数据到结果) │
│ │
└─────────────────────────────────────────────────────────────────────┘
深度学习 vs 传统机器学习¶
传统ML vs 深度学习¶

图注:传统ML vs 深度学习
┌─────────────────────────────────────────────────────────────────────┐
│ 传统ML vs 深度学习 工作流程对比 │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 传统机器学习 │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 原始数据 │───→│ 人工特征 │───→│ 特征向量 │───→│ 简单模型 │ │
│ │ (图像) │ │ 工程 │ │ (数值) │ │ (SVM等) │ │
│ └──────────┘ └──────────┘ └──────────┘ └──────────┘ │
│ ↑ ↓ │
│ 需要领域专家 输出 │
│ 设计特征 结果 │
│ │
│ 深度学习 │
│ ┌──────────┐ ┌──────────────────────────────────┐ ┌────────┐ │
│ │ 原始数据 │───→│ 深度神经网络(自动学习特征) │───→│ 输出结果│ │
│ │ (图像) │ │ 层1: 边缘 → 层2: 纹理 → 层3: 对象 │ │ │ │
│ └──────────┘ └──────────────────────────────────┘ └────────┘ │
│ ↑ ↓ │
│ 端到端学习 预测 │
│ 无需人工干预 结果 │
│ │
│ 核心优势:深度学习自动学习特征,减少人工干预 │
│ │
└─────────────────────────────────────────────────────────────────────┘
详细对比:
| 特性 | 传统机器学习 | 深度学习 |
|---|---|---|
| 特征工程 | 需要人工设计特征 | 自动学习特征 |
| 数据需求 | 小数据集即可工作 | 需要大量数据 |
| 计算需求 | CPU即可 | 通常需要GPU |
| 模型复杂度 | 相对简单 | 复杂(百万到十亿参数) |
| 可解释性 | 较好 | 较差("黑盒") |
| 适用数据 | 结构化数据 | 图像、文本、语音等非结构化数据 |
| 训练时间 | 较短 | 较长(小时到天数) |
| 调参难度 | 相对简单 | 较复杂(学习率、网络结构等) |
🧠 核心理论:表示学习¶
什么是表示学习?¶
表示学习(Representation Learning)是深度学习的核心思想:让机器自动从原始数据中学习有用的特征表示,而不是依赖人工设计的特征。
┌─────────────────────────────────────────────────────────────────────┐
│ 表示学习的核心思想 │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 原始数据空间 学习到的表示空间 │
│ (高维、复杂) (低维、结构化) │
│ │
│ 🐱 ● │
│ 猫照片 │ │
│ ↓ │ │
│ ┌─────────┐ │ │
│ │ 表示学习 │──────────────────→│ │
│ │ 网络 │ │ │
│ └─────────┘ │ │
│ ↓ ↓ │
│ [0.2, 0.8, ● 相似的样本 │
│ 0.1, 0.9] 在表示空间中 │
│ 784维像素 距离更近 │
│ │
│ 关键洞察: │
│ • 好的表示应该保留数据的语义结构 │
│ • 相似的输入应该有相似的表示 │
│ • 表示应该对不重要的变化(如光照、角度)具有不变性 │
│ │
└─────────────────────────────────────────────────────────────────────┘

图:表示学习:从原始数据空间到学习到的表示空间
层次化表示学习¶
深度学习的强大之处在于层次化的表示学习:
┌─────────────────────────────────────────────────────────────────────┐
│ 层次化特征学习:以图像识别为例 │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 输入图像 第1层 第2层 第3层 输出 │
│ ┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐ │
│ │ 🐱 │ → │ ─── │ → │ 👁️ │ → │ 🐱 │ → │ cat │ │
│ │ 照片 │ │ 边缘 │ │ 眼睛 │ │ 猫头 │ │ 0.95│ │
│ └─────┘ └─────┘ └─────┘ └─────┘ └─────┘ │
│ │
│ 特征层次: │
│ • 第1层(低级特征):边缘、颜色、纹理 │
│ • 第2层(中级特征):眼睛、耳朵、鼻子等部件 │
│ • 第3层(高级特征):猫头、猫身等整体特征 │
│ • 输出层:类别概率(猫、狗、鸟...) │
│ │
│ 关键洞察:每一层学习前一层的组合特征,形成层次化表示 │
│ │
└─────────────────────────────────────────────────────────────────────┘
为什么深度网络能学习更好的表示?¶
┌─────────────────────────────────────────────────────────────────────┐
│ 深度 vs 宽度:为什么深度更重要? │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 理论直觉: │
│ │
│ 浅层网络(宽但浅) 深层网络(窄但深) │
│ │
│ ┌───┐ ┌───┐ │
│ ──→│ │──┐ ──→│ │──┐ │
│ │ │ │ └───┘ │ │
│ ──→│ │──┼──→ ↓ │ │
│ │ │ │ ┌───┐ │ │
│ ──→│ │──┘ ──→│ │──┤ │
│ └───┘ └───┘ │ │
│ 单层,1000个神经元 ↓ │ │
│ ┌───┐ │ │
│ ──→│ │──┤ │
│ └───┘ │ │
│ ↓ │ │
│ ┌───┐ │ │
│ ──→│ │──┘ │
│ └───┘ │
│ 5层,每层20个神经元 │
│ │
│ 数学原理: │
│ • 深层网络可以用指数级更少的参数表示复杂函数 │
│ • 每层进行非线性变换,组合能力呈指数增长 │
│ • 深层结构符合现实世界的层次化结构(如图像的边→部件→对象) │
│ │
│ 例子:识别"猫" │
│ • 浅层:需要直接学习从像素到"猫"的映射(极其困难) │
│ • 深层:先学边缘,再学部件,再学对象(每步都简单) │
│ │
└─────────────────────────────────────────────────────────────────────┘
表示学习的数学视角¶
从数学角度看,深度学习是在学习一个从输入空间到表示空间的映射:
┌─────────────────────────────────────────────────────────────────────┐
│ 表示学习的数学形式 │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 深度神经网络作为函数组合: │
│ │
│ f(x) = f_L ∘ f_{L-1} ∘ ... ∘ f_2 ∘ f_1(x) │
│ │
│ 其中每层:f_l(z) = σ(W_l · z + b_l) │
│ │
│ 学习到的层次化表示: │
│ │
│ h_1 = f_1(x) # 第一层表示(低级特征) │
│ h_2 = f_2(h_1) # 第二层表示(中级特征) │
│ h_3 = f_3(h_2) # 第三层表示(高级特征) │
│ ... │
│ h_L = f_L(h_{L-1}) # 最终表示(用于分类/预测) │
│ │
│ 优化目标: │
│ min_θ E[Loss(f(x; θ), y)] │
│ │
│ 即:找到最优参数θ,使得网络输出与真实标签的差异最小 │
│ │
└─────────────────────────────────────────────────────────────────────┘
📈 深度学习发展简史¶
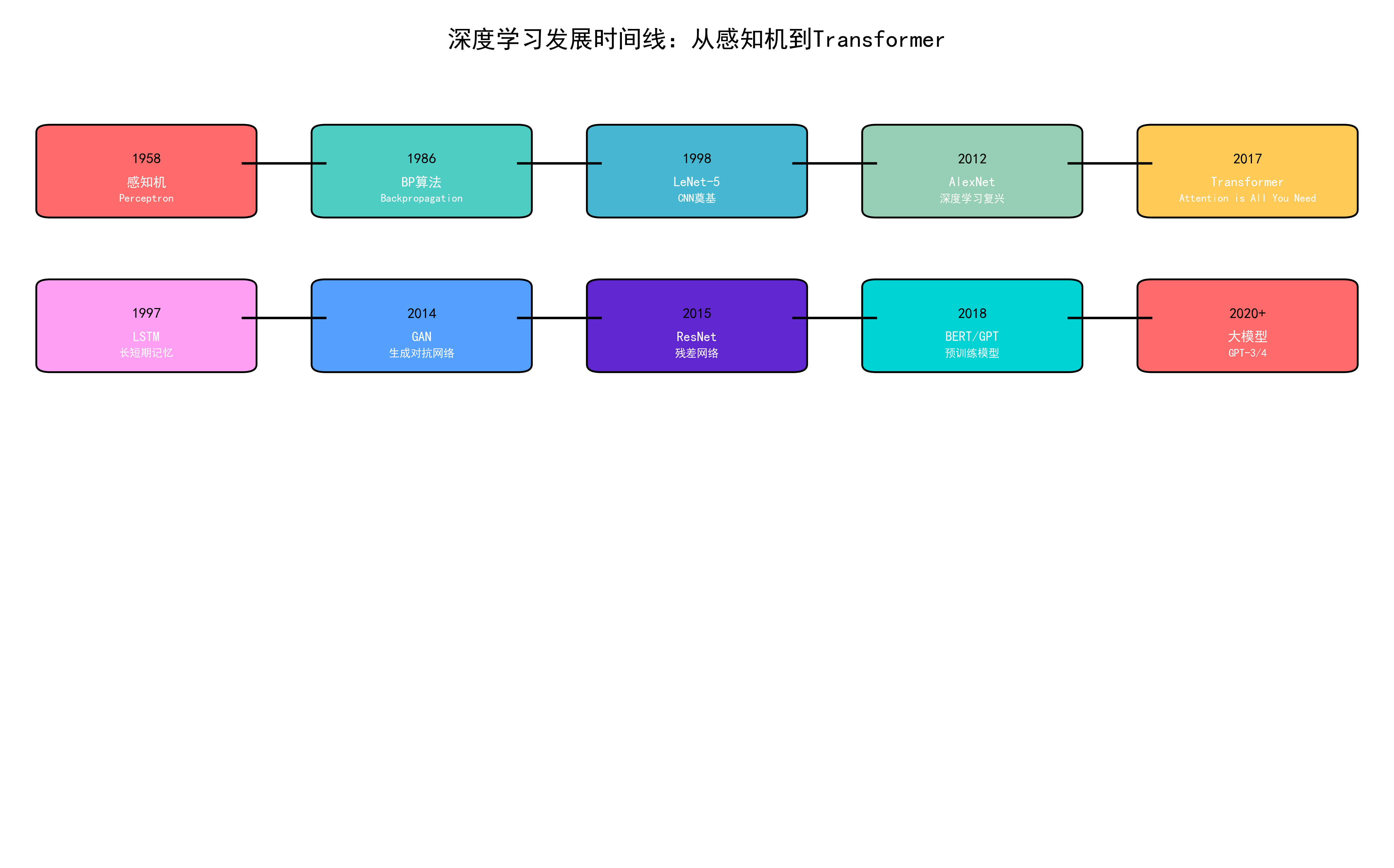
图注:深度学习发展时间线
关键里程碑¶
┌─────────────────────────────────────────────────────────────────────┐
│ 深度学习发展时间线 │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 1943 ───┐ │
│ │ McCulloch-Pitts神经元模型 │
│ │ 首次提出人工神经元数学模型 │
│ ↓ │
│ 1958 ───┐ │
│ │ Rosenblatt提出感知机(Perceptron) │
│ │ 第一个可学习的神经网络 │
│ ↓ │
│ 1969 ───┐ │
│ │ Minsky & Papert《Perceptrons》 │
│ │ 指出单层感知机的局限性,引发第一次AI寒冬 │
│ ↓ │
│ 1986 ───┐ │
│ │ Rumelhart等提出反向传播算法 │
│ │ ⭐ 使训练多层网络成为可能 │
│ ↓ │
│ 1998 ───┐ │
│ │ LeCun提出LeNet-5 │
│ │ 第一个成功的CNN,用于手写数字识别 │
│ ↓ │
│ 2006 ───┐ │
│ │ Hinton提出"深度学习"概念 │
│ │ 使用逐层预训练解决深层网络训练困难 │
│ ↓ │
│ 2012 ───┐ │
│ │ AlexNet赢得ImageNet竞赛 │
│ │ ⭐ 深度学习爆发点,错误率相对降低约41% │
│ ↓ │
│ 2014 ───┐ │
│ │ GAN(生成对抗网络) │
│ │ VGGNet(更深的网络) │
│ ↓ │
│ 2015 ───┐ │
│ │ ResNet(残差网络,152层) │
│ │ 解决深层网络的梯度消失问题 │
│ │ 超越人类在ImageNet上的表现 │
│ ↓ │
│ 2017 ───┐ │
│ │ Transformer架构(Attention Is All You Need) │
│ │ ⭐ 开启NLP新时代 │
│ ↓ │
│ 2018 ───┐ │
│ │ BERT(双向编码器) │
│ │ 预训练+微调范式 │
│ ↓ │
│ 2020 ───┐ │
│ │ GPT-3(1750亿参数) │
│ │ 展现出惊人的 few-shot 学习能力 │
│ ↓ │
│ 2022 ───┐ │
│ │ ChatGPT发布 │
│ │ Stable Diffusion开源 │
│ │ ⭐ AI进入大众视野 │
│ ↓ │
│ 2023+ ───┐ │
│ │ GPT-4、Claude等大模型 │
│ │ 多模态大模型(图像+文本) │
│ │ AI Agent、具身智能 │
│ │
└─────────────────────────────────────────────────────────────────────┘
为什么2012年是转折点?¶
AlexNet的成功标志着深度学习时代的到来:
┌─────────────────────────────────────────────────────────────────────┐
│ ImageNet竞赛错误率变化 │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 错误率% │
│ 30 ┤ │
│ │ ┌───┐ │
│ 25 ┤ │ │ │
│ │ │ │ ┌───┐ │
│ 20 ┤ │ │ │ │ ┌───┐ │
│ │ │ │ │ │ │ │ │
│ 15 ┤ │ │ │ │ │ │ ┌───┐ │
│ │ │ │ │ │ │ │ │ │ ┌───┐ │
│ 10 ┤ │ │ │ │ │ │ │ │ │ │ │
│ │ │ │ │ │ │ │ │ │ │ │ ┌───┐ │
│ 5 ┤ │ │ │ │ │ │ │ │ │ │ │ │ │
│ │ │ │ │ │ │ │ │ │ │ │ │ │ │
│ 0 ┼────┴───┴────┴───┴────┴───┴────┴───┴────┴───┴────┴───┤ │
│ 2010 2011 2012 2013 2014 2015 2016 2017 2018 │
│ │
│ 传统方法 │ AlexNet │ 深度学习时代 │
│ 26.2% 15.3% 3.57% │
│ │
│ 2012年AlexNet将错误率从26.2%降至15.3%,震惊学术界 │
│ │
└─────────────────────────────────────────────────────────────────────┘
AlexNet成功的关键因素: 1. 大规模数据:ImageNet有100万张标注图像 2. 强大算力:使用GPU加速训练 3. 算法创新:ReLU激活函数、Dropout正则化 4. 更深的网络:8层(当时算很深)
🎯 深度学习的核心思想¶
1. 端到端学习¶
┌─────────────────────────────────────────────────────────────────────┐
│ 端到端学习 vs 多阶段流程 │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 传统方法(语音识别为例): │
│ │
│ 音频 → 特征提取 → 音素识别 → 单词识别 → 语言模型 → 文本 │
│ ↑ ↑ ↑ ↑ ↑ │
│ └───────┴──────────┴──────────┴──────────┘ │
│ 每个阶段独立优化,误差累积 │
│ │
│ 深度学习方法(端到端): │
│ │
│ 音频 ─────────────────────────────────────────────→ 文本 │
│ ↑ ↑ │
│ └──────────────── 深度神经网络 ────────────────────┘ │
│ │
│ 统一优化,自动学习中间表示 │
│ │
│ 优势: │
│ • 减少人工设计 │
│ • 全局优化 │
│ • 潜在性能更好 │
│ │
└─────────────────────────────────────────────────────────────────────┘
2. 数据驱动¶
┌─────────────────────────────────────────────────────────────────────┐
│ 数据:深度学习的燃料 │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 数据规模与模型性能关系: │
│ │
│ 准确率 │
│ ↑ │
│ 100┤ ╭──── 深度学习 │
│ │ ╭────╯ │
│ 80┤ ╭────╯ │
│ │ ╭────╯ │
│ 60┤ ╭────╯ │
│ │ ╭────╯ │
│ 40┤ ╭────╯ ╭──── 传统ML │
│ │ ╭────╯ ╭────╯ │
│ 20┤─╯ ╭────╯ │
│ │ ╭────╯ │
│ 0┼────────────────────────────────────────→ 数据量 │
│ 小 中 大 非常大 │
│ │
│ 关键洞察: │
│ • 小数据:传统ML可能更好(不易过拟合) │
│ • 大数据:深度学习显著优于传统方法 │
│ • 数据是深度学习的核心资产 │
│ │
└─────────────────────────────────────────────────────────────────────┘
3. 可微分编程¶
深度学习的一个革命性思想是可微分编程:任何可微分的计算都可以用神经网络表示并自动优化。
┌─────────────────────────────────────────────────────────────────────┐
│ 可微分编程:深度学习的核心机制 │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 核心思想: │
│ 只要计算过程是可微分的,就可以用梯度下降优化 │
│ │
│ 计算图示例: │
│ │
│ x ───┐ │
│ ├──→ [×] ──→ z ──→ [+] ──→ a ──→ [σ] ──→ y │
│ w ───┘ ↑ │
│ b │
│ │
│ 前向传播:计算输出 │
│ z = x * w │
│ a = z + b │
│ y = σ(a) # σ是sigmoid函数 │
│ │
│ 反向传播:计算梯度 │
│ ∂L/∂y → ∂L/∂a → ∂L/∂z → ∂L/∂w, ∂L/∂b │
│ │
│ 链式法则自动应用! │
│ │
│ 应用: │
│ • 传统神经网络层(全连接、卷积、RNN) │
│ • 自定义操作(只要可微分) │
│ • 神经架构搜索(NAS) │
│ • 可微分渲染、物理模拟 │
│ │
└─────────────────────────────────────────────────────────────────────┘
🌐 深度学习的应用领域¶

图注:深度学习在各领域的应用
计算机视觉¶
┌─────────────────────────────────────────────────────────────────────┐
│ 计算机视觉应用 │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 图像分类 目标检测 图像分割 │
│ ┌─────┐ ┌─────┐ ┌─────┐ │
│ │ 🐱 │ │ 🐱📦 │ │ 🐱▓▓▓│ │
│ │ cat │ │cat:0.95│ │▓cat▓│ │
│ │0.95 │ └─────┘ └─────┘ │
│ └─────┘ │
│ │
│ 人脸识别 图像生成 视频分析 │
│ ┌─────┐ ┌─────┐ ┌─────┐ │
│ │ 👤✓ │ │ 🎨→🖼️ │ │ 🎬→📊 │ │
│ │匹配 │ │文本→图像│ │动作识别│ │
│ └─────┘ └─────┘ └─────┘ │
│ │
│ 应用实例: │
│ • 医学影像诊断(肿瘤检测) │
│ • 自动驾驶(障碍物检测) │
│ • 工业质检(缺陷检测) │
│ • 人脸识别解锁 │
│ │
└─────────────────────────────────────────────────────────────────────┘
自然语言处理¶
┌─────────────────────────────────────────────────────────────────────┐
│ 自然语言处理应用 │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 机器翻译 文本生成 情感分析 │
│ ┌────────┐ ┌────────┐ ┌────────┐ │
│ │Hello │ → │写一篇 │ → │"太棒了!"│ │
│ │→ 你好 │ │关于AI │ │→ 正面 │ │
│ │ │ │的文章 │ │0.92 │ │
│ └────────┘ └────────┘ └────────┘ │
│ │
│ 问答系统 语音识别 文本摘要 │
│ ┌────────┐ ┌────────┐ ┌────────┐ │
│ │Q: 什么是│ │🎤→"今天 │ │长文章 │ │
│ │ 深度学习│ │ 天气很好"│ │→ 摘要 │ │
│ │A: ... │ │→ 文本 │ │ │ │
│ └────────┘ └────────┘ └────────┘ │
│ │
│ 应用实例: │
│ • ChatGPT、Claude等对话助手 │
│ • 智能客服 │
│ • 语音助手(Siri、小爱同学) │
│ • 机器翻译(Google翻译、DeepL) │
│ │
└─────────────────────────────────────────────────────────────────────┘
其他重要领域¶
| 领域 | 典型应用 | 代表模型/技术 |
|---|---|---|
| 推荐系统 | 商品推荐、内容推荐 | DeepFM、Wide&Deep |
| 游戏AI | 围棋、星际争霸 | AlphaGo、AlphaStar |
| 机器人 | 机械臂控制、导航 | 强化学习+深度学习 |
| 科学计算 | 蛋白质结构预测、药物发现 | AlphaFold、GNN |
| 艺术创作 | 图像生成、音乐生成 | GAN、扩散模型 |
⚖️ 深度学习的优势与局限¶
优势¶
┌─────────────────────────────────────────────────────────────────────┐
│ 深度学习的优势 │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 1. 自动特征学习 │
│ ┌─────────────────────────────────────────┐ │
│ │ 不需要人工设计特征,网络自动学习最优表示 │ │
│ │ 例:CNN自动学习从边缘到对象的层次特征 │ │
│ └─────────────────────────────────────────┘ │
│ │
│ 2. 端到端训练 │
│ ┌─────────────────────────────────────────┐ │
│ │ 直接从原始数据到最终输出,减少中间环节 │ │
│ │ 例:语音识别直接从音频到文本 │ │
│ └─────────────────────────────────────────┘ │
│ │
│ 3. 强大的表达能力 │
│ ┌─────────────────────────────────────────┐ │
│ │ 深层网络可以学习极其复杂的函数映射 │ │
│ │ 例:GPT-4能生成人类水平的文章 │ │
│ └─────────────────────────────────────────┘ │
│ │
│ 4. 泛化能力强 │
│ ┌─────────────────────────────────────────┐ │
│ │ 在大规模数据上训练后,能泛化到新数据 │ │
│ │ 例:预训练模型+微调适应新任务 │ │
│ └─────────────────────────────────────────┘ │
│ │
│ 5. 可迁移学习 │
│ ┌─────────────────────────────────────────┐ │
│ │ 在一个任务上学到的知识可以迁移到新任务 │ │
│ │ 例:ImageNet预训练模型用于医学图像 │ │
│ └─────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────────┘
局限¶
┌─────────────────────────────────────────────────────────────────────┐
│ 深度学习的局限 │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 1. 数据饥渴 │
│ ┌─────────────────────────────────────────┐ │
│ │ 需要大量标注数据才能发挥性能 │ │
│ │ 例:ImageNet有100万张标注图像 │ │
│ │ 解决:数据增强、迁移学习、自监督学习 │ │
│ └─────────────────────────────────────────┘ │
│ │
│ 2. 计算资源需求高 │
│ ┌─────────────────────────────────────────┐ │
│ │ 训练大模型需要昂贵的GPU集群 │ │
│ │ 例:GPT-3训练成本约460万美元 │ │
│ │ 解决:模型压缩、高效架构、云计算 │ │
│ └─────────────────────────────────────────┘ │
│ │
│ 3. 可解释性差(黑盒问题) │
│ ┌─────────────────────────────────────────┐ │
│ │ 难以解释模型为什么做出某个决策 │ │
│ │ 例:医疗AI诊断,医生需要知道原因 │ │
│ │ 解决:可解释AI(XAI)、注意力可视化 │ │
│ └─────────────────────────────────────────┘ │
│ │
│ 4. 对抗样本脆弱性 │
│ ┌─────────────────────────────────────────┐ │
│ │ 微小扰动能导致模型完全错误 │ │
│ │ 例:熊猫图片加噪声被识别为长臂猿 │ │
│ │ 解决:对抗训练、防御方法 │ │
│ └─────────────────────────────────────────┘ │
│ │
│ 5. 偏见与公平性问题 │
│ ┌─────────────────────────────────────────┐ │
│ │ 模型会学习训练数据中的偏见 │ │
│ │ 例:人脸识别对某些种族准确率较低 │ │
│ │ 解决:公平性约束、多样化数据集 │ │
│ └─────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────────────┘
🚀 2024深度学习前沿动态¶
大语言模型(LLM)革命¶
┌─────────────────────────────────────────────────────────────────────┐
│ 大语言模型发展现状(2024) │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 模型规模增长: │
│ │
│ GPT-1 (2018) ──→ 1.17亿参数 │
│ ↓ │
│ GPT-2 (2019) ──→ 15亿参数 │
│ ↓ │
│ GPT-3 (2020) ──→ 1750亿参数 │
│ ↓ │
│ GPT-4 (2023) ──→ 参数量未公开(MoE架构) │
│ ↓ │
│ GPT-4o (2024) ──→ 原生多模态,实时交互 │
│ │
│ 2024关键趋势: │
│ • 多模态融合:文本、图像、音频、视频统一处理 │
│ • 推理能力增强:Chain-of-Thought、Self-Consistency │
│ • 效率优化:模型压缩、量化、蒸馏 │
│ • 长上下文:支持百万token级别的上下文 │
│ • Agent能力:自主规划、工具使用、多轮交互 │
│ • 架构创新:MLA(多头潜在注意力)等高效注意力机制 │
│ │
└─────────────────────────────────────────────────────────────────────┘
### Transformer架构优化:MLA(多头潜在注意力)
```text
┌─────────────────────────────────────────────────────────────────────┐
│ MLA:高效注意力机制 │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 背景: │
│ 传统Transformer的多头注意力(MHA)在推理时需要缓存完整的KV缓存, │
│ 导致内存占用随序列长度线性增长,限制了长上下文处理能力。 │
│ │
│ MLA(Multi-head Latent Attention)创新: │
│ │
│ ┌─────────────────────────────────────────────────────────────┐ │
│ │ 核心思想:低秩压缩KV缓存 │ │
│ │ │ │
│ │ 传统MHA: │ │
│ │ • Key/Value维度 = head_dim × num_heads │ │
│ │ • 缓存大小 = seq_len × head_dim × num_heads × batch_size │ │
│ │ │ │
│ │ MLA: │ │
│ │ • 将KV投影到低维潜在空间(latent space) │ │
│ │ • 缓存大小 = seq_len × latent_dim × batch_size │ │
│ │ • latent_dim << head_dim × num_heads │ │
│ │ │ │
│ │ 效果:内存占用减少50-90%,推理速度显著提升 │ │
│ └─────────────────────────────────────────────────────────────┘ │
│ │
│ 代表模型:DeepSeek-V2/V3(2024) │
│ • 采用MLA架构,在保持性能的同时大幅降低推理成本 │
│ • 开源模型,推动了高效大模型的发展 │
│ │
│ 意义: │
│ • 使长上下文模型(100万+ token)在实际应用中可行 │
│ • 降低了大模型部署的硬件门槛 │
│ │
└─────────────────────────────────────────────────────────────────────┘
生成式AI突破¶
┌─────────────────────────────────────────────────────────────────────┐
│ 生成式AI技术演进(2024) │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 图像生成: │
│ • Stable Diffusion 3:更好的文本理解和图像质量 │
│ • DALL-E 3:与ChatGPT集成,提示词理解更强 │
│ • Midjourney V6: photorealistic图像生成 │
│ • 视频生成:Sora、Runway Gen-2实现高质量视频生成 │
│ │
│ 音频生成: │
│ • 语音克隆:几秒钟音频即可克隆声音 │
│ • 音乐生成:Suno、Udio实现完整歌曲创作 │
│ • 实时语音合成:延迟低于100ms │
│ │
│ 代码生成: │
│ • GitHub Copilot:支持多文件编辑、代码审查、测试生成等 │
│ • Claude 3.5 Sonnet:代码理解和生成能力显著提升 │
│ • Devin(Cognition Labs):以"AI软件工程师"定位引发广泛关注, │
│ 实际独立完成复杂任务的能力仍在持续迭代中 │
│ │
│ 关键技术: │
│ • 扩散模型(Diffusion Models) │
│ • 流匹配(Flow Matching) │
│ • 一致性模型(Consistency Models) │
│ │
└─────────────────────────────────────────────────────────────────────┘
AI Agent与具身智能¶
┌─────────────────────────────────────────────────────────────────────┐
│ AI Agent与具身智能(2024) │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ AI Agent架构: │
│ │
│ ┌─────────────────────────────────────────────────────────────┐ │
│ │ AI Agent │ │
│ │ │ │
│ │ ┌──────────┐ ┌──────────┐ ┌──────────┐ │ │
│ │ │ 感知模块 │───→│ 规划模块 │───→│ 执行模块 │ │ │
│ │ │(视觉/文本)│ │(推理/决策)│ │(工具调用) │ │ │
│ │ └──────────┘ └──────────┘ └──────────┘ │ │
│ │ ↑ ↓ │ │
│ │ ┌──────────────────────────────────────┐ │ │
│ │ │ 记忆模块 │ │ │
│ │ │ (短期记忆 + 长期记忆 + 知识库) │ │ │
│ │ └──────────────────────────────────────┘ │ │
│ │ │ │
│ └─────────────────────────────────────────────────────────────┘ │
│ │
│ 2024重要进展: │
│ • AutoGPT、LangChain等Agent框架成熟 │
│ • 多Agent协作系统 │
│ • 具身智能:Figure AI、Tesla Optimus等人形机器人 │
│ • 端到端自动驾驶:Tesla FSD V12 │
│ │
└─────────────────────────────────────────────────────────────────────┘
🧪 动手实验:你的第一个神经网络¶
让我们用PyTorch实现一个简单的神经网络,体验深度学习的魅力。
实验目标¶
训练一个神经网络来识别手写数字(MNIST数据集)。
代码实现¶
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
# 1. 数据准备
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST('./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True) # DataLoader批量加载数据,支持shuffle和多进程
# 2. 定义神经网络
class SimpleNet(nn.Module):
def __init__(self): # __init__构造方法,创建对象时自动调用
super().__init__() # super()调用父类方法
self.flatten = nn.Flatten()
self.fc1 = nn.Linear(28*28, 128) # 输入层 → 隐藏层
self.relu = nn.ReLU() # 激活函数
self.fc2 = nn.Linear(128, 10) # 隐藏层 → 输出层
def forward(self, x):
x = self.flatten(x) # 将28x28图像展平为784维向量
x = self.fc1(x) # 线性变换: 784 → 128
x = self.relu(x) # 非线性激活
x = self.fc2(x) # 线性变换: 128 → 10
return x
# 3. 创建模型、损失函数和优化器
model = SimpleNet()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 4. 训练循环
print("开始训练...")
for epoch in range(5): # 训练5轮
total_loss = 0
for batch_idx, (data, target) in enumerate(train_loader): # enumerate同时获取索引和元素
# 前向传播
output = model(data)
loss = criterion(output, target)
# 反向传播
optimizer.zero_grad()
loss.backward() # 反向传播计算梯度
optimizer.step() # 根据梯度更新模型参数
total_loss += loss.item() # .item()将单元素张量转为Python数值
if batch_idx % 100 == 0:
print(f'Epoch: {epoch}, Batch: {batch_idx}, Loss: {loss.item():.4f}')
print(f'Epoch {epoch} 完成, 平均损失: {total_loss/len(train_loader):.4f}')
print("训练完成!")
运行结果¶
开始训练...
Epoch: 0, Batch: 0, Loss: 2.3125
Epoch: 0, Batch: 100, Loss: 0.8542
Epoch: 0, Batch: 200, Loss: 0.5231
...
Epoch 0 完成, 平均损失: 0.6123
Epoch 1 完成, 平均损失: 0.3245
...
训练完成!
观察:损失逐渐下降,说明网络正在学习!
💡 核心要点总结¶
深度学习的本质¶
- 表示学习:自动从数据中学习层次化特征表示
- 多层神经网络:通过多层非线性变换学习复杂映射
- 端到端训练:直接从数据学习映射关系
- 数据驱动:性能随数据量增加而提升
- 可微分编程:任何可微分计算都可自动优化
关键里程碑¶
- 1943:McCulloch-Pitts神经元模型
- 1986:反向传播算法
- 2012:AlexNet开启深度学习时代
- 2017:Transformer架构
- 2022:ChatGPT引发AI热潮
- 2024:多模态大模型、AI Agent、具身智能
主要应用领域¶
- 计算机视觉(图像分类、目标检测、分割)
- 自然语言处理(翻译、生成、问答)
- 推荐系统、游戏AI、科学计算
- 生成式AI(图像、音频、视频、代码)
优势与局限¶
优势:自动特征学习、端到端训练、强大表达能力、可迁移学习 局限:数据饥渴、计算需求高、可解释性差
❓ 常见问题¶
Q1:深度学习和机器学习有什么区别?
A:深度学习是机器学习的一个子集,特指使用深层神经网络的机器学习方法。主要区别: - 深度学习自动学习特征,传统ML需要人工设计特征 - 深度学习需要更多数据和计算资源 - 深度学习在图像、语音、文本等非结构化数据上表现更好
Q2:为什么叫"深度"学习?
A:"深度"指的是神经网络的层数。传统神经网络通常只有1-2层隐藏层,而深度学习网络有3层以上(现代网络可达100+层)。深层结构使网络能学习更复杂的特征层次。
Q3:没有GPU可以学习深度学习吗?
A:完全可以! - 理论学习不需要GPU - 小模型(如MNIST分类)在CPU上也能训练 - 可以使用Google Colab等免费GPU资源 - 本教程会提供适合CPU运行的版本
Q4:深度学习需要很强的数学基础吗?
A:基础数学即可: - 线性代数(矩阵运算) - 微积分(导数、梯度) - 概率论(概率分布、期望) - 统计学(均值、方差)
本教程会尽量用直观方式解释数学概念,附录也有数学速查。
Q5:深度学习的未来发展方向是什么?
A:主要方向包括: - 大模型:更大规模、更强能力 - 多模态:融合文本、图像、音频、视频 - 具身智能:AI与物理世界交互 - AI Agent:自主决策和任务执行 - 可解释性:让AI决策更透明 - 高效化:降低训练和推理成本 - AI安全与对齐:确保AI行为符合人类价值观
📝 自测问题¶
- 什么是深度学习?与传统机器学习的主要区别是什么?
- 什么是表示学习?为什么层次化表示很重要?
- 为什么2012年是深度学习的转折点?
- 深度学习的三个核心思想是什么?
- 列举深度学习的三个优势和三个局限。
- 2024年深度学习有哪些重要进展?
📚 扩展阅读¶
- 《Deep Learning》 - Goodfellow et al.(深度学习圣经)
- 《Neural Networks and Deep Learning》 - Michael Nielsen(免费在线)
- CS231n - Stanford深度学习课程
- 3Blue1Brown神经网络系列 - YouTube可视化讲解
- Attention Is All You Need - Transformer原始论文
- Deep Residual Learning for Image Recognition - ResNet论文
🎯 下一步¶
继续学习 02-神经网络基础,深入了解感知机和多层神经网络的工作原理。